 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimal Model Reasoning in Description Logics: Don't Try This at Home!
Aug 07, 2025Reasoning with minimal models has always been at the core of many knowledge representation techniques, but we still have only a limited understanding of this problem in Description Logics (DLs). Minimization of some selected predicates, letting the remaining predicates vary or be fixed, as proposed in circumscription, has been explored and exhibits high complexity. The case of `pure' minimal models, where the extension of all predicates must be minimal, has remained largely uncharted. We address this problem in popular DLs and obtain surprisingly negative results: concept satisfiability in minimal models is undecidable already for $\mathcal{EL}$. This undecidability also extends to a very restricted fragment of tuple-generating dependencies. To regain decidability, we impose acyclicity conditions on the TBox that bring the worst-case complexity below double exponential time and allow us to establish a connection with the recently studied pointwise circumscription; we also derive results in data complexity. We conclude with a brief excursion to the DL-Lite family, where a positive result was known for DL-Lite$_{\text{core}}$, but our investigation establishes ExpSpace-hardness already for its extension DL-Lite$_{\text{horn}}$.
SHACL Validation under Graph Updates (Extended Paper)
Jul 31, 2025SHACL (SHApe Constraint Language) is a W3C standardized constraint language for RDF graphs. In this paper, we study SHACL validation in RDF graphs under updates. We present a SHACL-based update language that can capture intuitive and realistic modifications on RDF graphs and study the problem of static validation under such updates. This problem asks to verify whether every graph that validates a SHACL specification will still do so after applying a given update sequence. More importantly, it provides a basis for further services for reasoning about evolving RDF graphs. Using a regression technique that embeds the update actions into SHACL constraints, we show that static validation under updates can be reduced to (un)satisfiability of constraints in (a minor extension of) SHACL. We analyze the computational complexity of the static validation problem for SHACL and some key fragments. Finally, we present a prototype implementation that performs static validation and other static analysis tasks on SHACL constraints and demonstrate its behavior through preliminary experiments.
An ExpTime Upper Bound for $\mathcal{ALC}$ with Integers
Jun 03, 2020

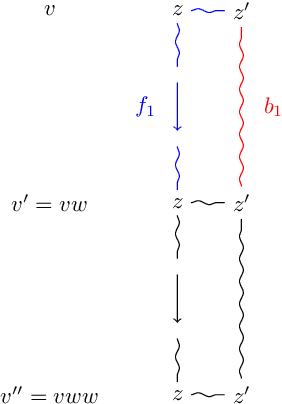
Concrete domains, especially those that allow to compare features with numeric values, have long been recognized as a very desirable extension of description logics (DLs), and significant efforts have been invested into adding them to usual DLs while keeping the complexity of reasoning in check. For expressive DLs and in the presence of general TBoxes, for standard reasoning tasks like consistency, the most general decidability results are for the so-called $\omega$-admissible domains, which are required to be dense. Supporting non-dense domains for features that range over integers or natural numbers remained largely open, despite often being singled out as a highly desirable extension. The decidability of some extensions of $\mathcal{ALC}$ with non-dense domains has been shown, but existing results rely on powerful machinery that does not allow to infer any elementary bounds on the complexity of the problem. In this paper, we study an extension of $\mathcal{ALC}$ with a rich integer domain that allows for comparisons (between features, and between features and constants coded in unary), and prove that consistency can be solved using automata-theoretic techniques in single exponential time, and thus has no higher worst-case complexity than standard $\mathcal{ALC}$. Our upper bounds apply to some extensions of DLs with concrete domains known from the literature, support general TBoxes, and allow for comparing values along paths of ordinary (not necessarily functional) roles.
Polynomial Rewritings from Expressive Description Logics with Closed Predicates to Variants of Datalog
Dec 16, 2019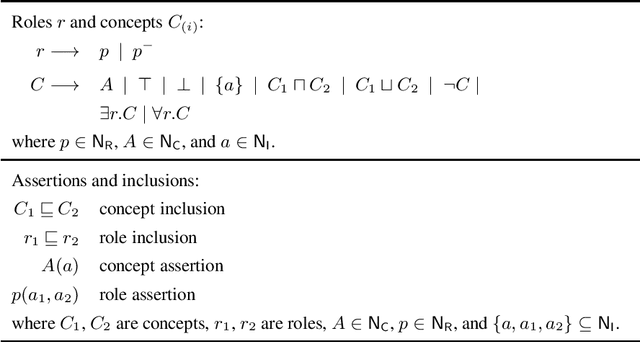
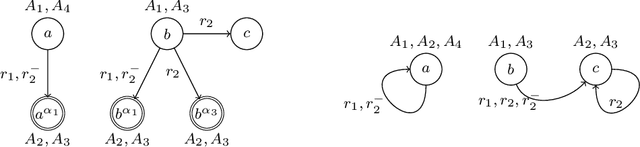


In many scenarios, complete and incomplete information coexist. For this reason, the knowledge representation and database communities have long shown interest in simultaneously supporting the closed- and the open-world views when reasoning about logic theories. Here we consider the setting of querying possibly incomplete data using logic theories, formalized as the evaluation of an ontology-mediated query (OMQ) that pairs a query with a theory, sometimes called an ontology, expressing background knowledge. This can be further enriched by specifying a set of closed predicates from the theory that are to be interpreted under the closed-world assumption, while the rest are interpreted with the open-world view. In this way we can retrieve more precise answers to queries by leveraging the partial completeness of the data. The central goal of this paper is to understand the relative expressiveness of OMQ languages in which the ontology is written in the expressive Description Logic (DL) ALCHOI and includes a set of closed predicates. We consider a restricted class of conjunctive queries. Our main result is to show that every query in this non-monotonic query language can be translated in polynomial time into Datalog with negation under the stable model semantics. To overcome the challenge that Datalog has no direct means to express the existential quantification present in ALCHOI, we define a two-player game that characterizes the satisfaction of the ontology, and design a Datalog query that can decide the existence of a winning strategy for the game. If there are no closed predicates, that is in the case of querying a plain ALCHOI knowledge base, our translation yields a positive disjunctive Datalog program of polynomial size. To the best of our knowledge, unlike previous translations for related fragments with expressive (non-Horn) DLs, these are the first polynomial time translations.
Relaxing and Restraining Queries for OBDA
Aug 08, 2018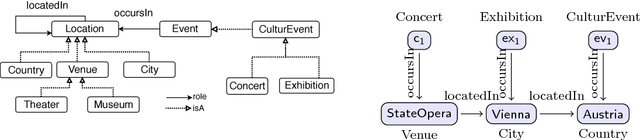
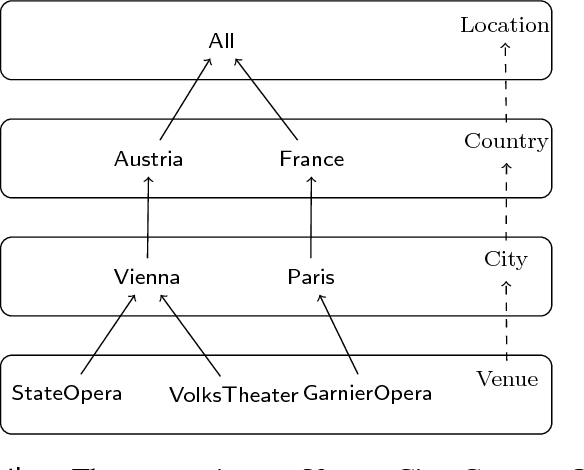
In ontology-based data access (OBDA), ontologies have been successfully employed for querying possibly unstructured and incomplete data. In this paper, we advocate using ontologies not only to formulate queries and compute their answers, but also for modifying queries by relaxing or restraining them, so that they can retrieve either more or less answers over a given dataset. Towards this goal, we first illustrate that some domain knowledge that could be naturally leveraged in OBDA can be expressed using complex role inclusions (CRI). Queries over ontologies with CRI are not first-order (FO) rewritable in general. We propose an extension of DL-Lite with CRI, and show that conjunctive queries over ontologies in this extension are FO rewritable. Our main contribution is a set of rules to relax and restrain conjunctive queries (CQs). Firstly, we define rules that use the ontology to produce CQs that are relaxations/restrictions over any dataset. Secondly, we introduce a set of data-driven rules, that leverage patterns in the current dataset, to obtain more fine-grained relaxations and restrictions.
Managing Change in Graph-structured Data Using Description Logics (long version with appendix)
May 29, 2014
In this paper, we consider the setting of graph-structured data that evolves as a result of operations carried out by users or applications. We study different reasoning problems, which range from ensuring the satisfaction of a given set of integrity constraints after a given sequence of updates, to deciding the (non-)existence of a sequence of actions that would take the data to an (un)desirable state, starting either from a specific data instance or from an incomplete description of it. We consider an action language in which actions are finite sequences of conditional insertions and deletions of nodes and labels, and use Description Logics for describing integrity constraints and (partial) states of the data. We then formalize the above data management problems as a static verification problem and several planning problems. We provide algorithms and tight complexity bounds for the formalized problems, both for an expressive DL and for a variant of DL-Lite.
Nested Regular Path Queries in Description Logics
Mar 04, 2014

Two-way regular path queries (2RPQs) have received increased attention recently due to their ability to relate pairs of objects by flexibly navigating graph-structured data. They are present in property paths in SPARQL 1.1, the new standard RDF query language, and in the XML query language XPath. In line with XPath, we consider the extension of 2RPQs with nesting, which allows one to require that objects along a path satisfy complex conditions, in turn expressed through (nested) 2RPQs. We study the computational complexity of answering nested 2RPQs and conjunctions thereof (CN2RPQs) in the presence of domain knowledge expressed in description logics (DLs). We establish tight complexity bounds in data and combined complexity for a variety of DLs, ranging from lightweight DLs (DL-Lite, EL) up to highly expressive ones. Interestingly, we are able to show that adding nesting to (C)2RPQs does not affect worst-case data complexity of query answering for any of the considered DLs. However, in the case of lightweight DLs, adding nesting to 2RPQs leads to a surprising jump in combined complexity, from P-complete to Exp-complete.
Reasoning about Explanations for Negative Query Answers in DL-Lite
Feb 04, 2014

In order to meet usability requirements, most logic-based applications provide explanation facilities for reasoning services. This holds also for Description Logics, where research has focused on the explanation of both TBox reasoning and, more recently, query answering. Besides explaining the presence of a tuple in a query answer, it is important to explain also why a given tuple is missing. We address the latter problem for instance and conjunctive query answering over DL-Lite ontologies by adopting abductive reasoning; that is, we look for additions to the ABox that force a given tuple to be in the result. As reasoning tasks we consider existence and recognition of an explanation, and relevance and necessity of a given assertion for an explanation. We characterize the computational complexity of these problems for arbitrary, subset minimal, and cardinality minimal explanations.