 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancement of Short Text Clustering by Iterative Classification
Jan 31, 2020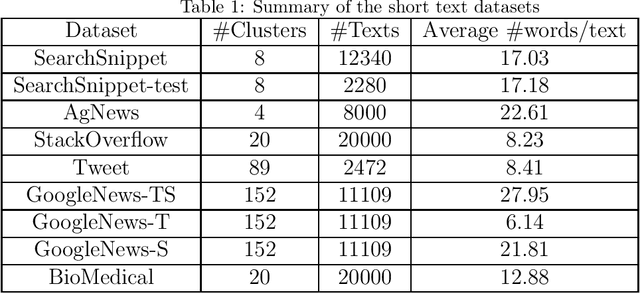
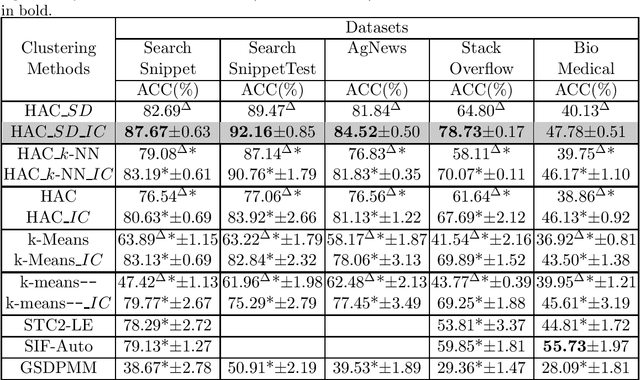
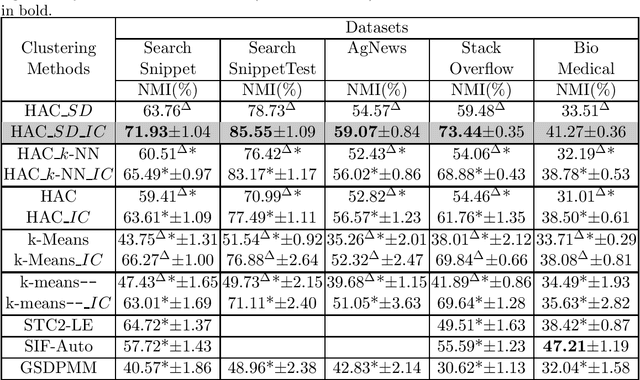
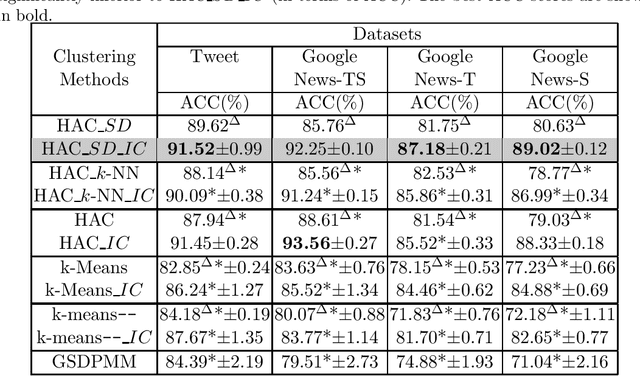
Short text clustering is a challenging task due to the lack of signal contained in such short texts. In this work, we propose iterative classification as a method to b o ost the clustering quality (e.g., accuracy) of short texts. Given a clustering of short texts obtained using an arbitrary clustering algorithm, iterative classification applies outlier removal to obtain outlier-free clusters. Then it trains a classification algorithm using the non-outliers based on their cluster distributions. Using the trained classification model, iterative classification reclassifies the outliers to obtain a new set of clusters. By repeating this several times, we obtain a much improved clustering of texts. Our experimental results show that the proposed clustering enhancement method not only improves the clustering quality of different clustering methods (e.g., k-means, k-means--, and hierarchical clustering) but also outperforms the state-of-the-art short text clustering methods on several short text datasets by a statistically significant margin.