 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Tangent Kernel Eigenvalues Accurately Predict Generalization
Oct 13, 2021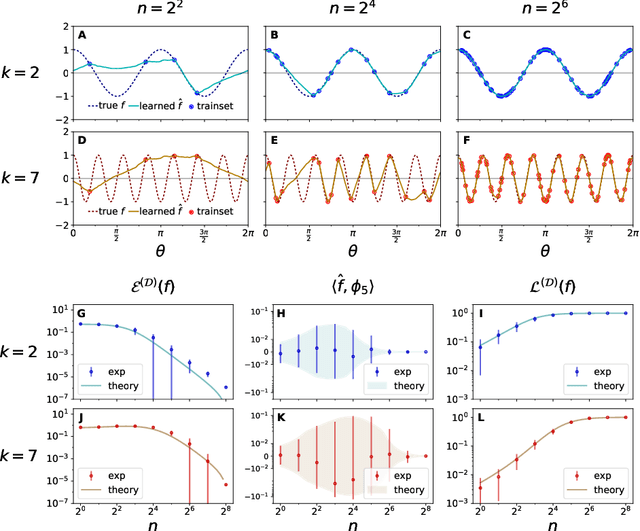
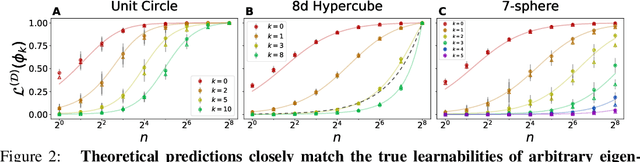
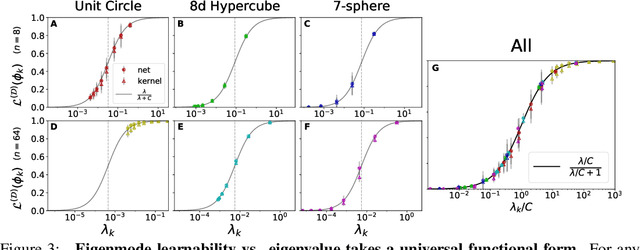
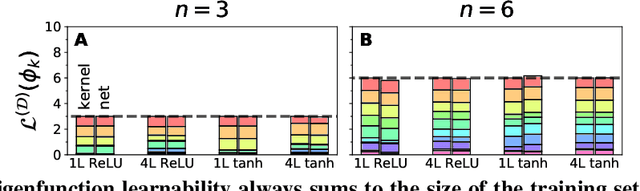
Finding a quantitative theory of neural network generalization has long been a central goal of deep learning research. We extend recent results to demonstrate that, by examining the eigensystem of a neural network's "neural tangent kernel", one can predict its generalization performance when learning arbitrary functions. Our theory accurately predicts not only test mean-squared-error but all first- and second-order statistics of the network's learned function. Furthermore, using a measure quantifying the "learnability" of a given target function, we prove a new "no-free-lunch" theorem characterizing a fundamental tradeoff in the inductive bias of wide neural networks: improving a network's generalization for a given target function must worsen its generalization for orthogonal functions. We further demonstrate the utility of our theory by analytically predicting two surprising phenomena - worse-than-chance generalization on hard-to-learn functions and nonmonotonic error curves in the small data regime - which we subsequently observe in experiments. Though our theory is derived for infinite-width architectures, we find it agrees with networks as narrow as width 20, suggesting it is predictive of generalization in practical neural networks. Code replicating our results is available at https://github.com/james-simon/eigenlearning.