 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving predictions of Bayesian neural networks via local linearization
Aug 19, 2020



In this paper we argue that in Bayesian deep learning, the frequently utilized generalized Gauss-Newton (GGN) approximation should be understood as a modification of the underlying probabilistic model and should be considered separately from further approximate inference techniques. Applying the GGN approximation turns a BNN into a locally linearized generalized linear model or, equivalently, a Gaussian process. Because we then use this linearized model for inference, we should also predict using this modified likelihood rather than the original BNN likelihood. This formulation extends previous results to general likelihoods and alleviates underfitting behaviour observed e.g. by Ritter et al. (2018). We demonstrate our approach on several UCI classification datasets as well as CIFAR10.
Approximate Inference Turns Deep Networks into Gaussian Processes
Jun 05, 2019
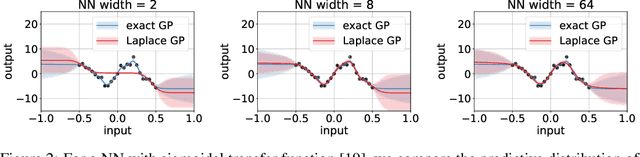
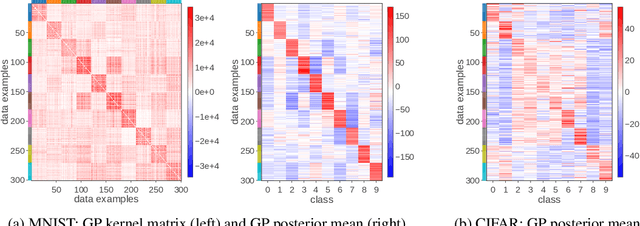

Deep neural networks (DNN) and Gaussian processes (GP) are two powerful models with several theoretical connections relating them, but the relationship between their training methods is not well understood. In this paper, we show that certain Gaussian posterior approximations for Bayesian DNNs are equivalent to GP posteriors. As a result, we can obtain a GP kernel and a nonlinear feature map simply by training the DNN. Surprisingly, the resulting kernel is the neural tangent kernel which has desirable theoretical properties for infinitely-wide DNNs. We show feature maps obtained on real datasets and demonstrate the use of the GP marginal likelihood to tune hyperparameters of DNNs. Our work aims to facilitate further research on combining DNNs and GPs in practical settings.