 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Temporal Fusion Transformers Are Good Product Demand Forecasters
Jul 05, 2023

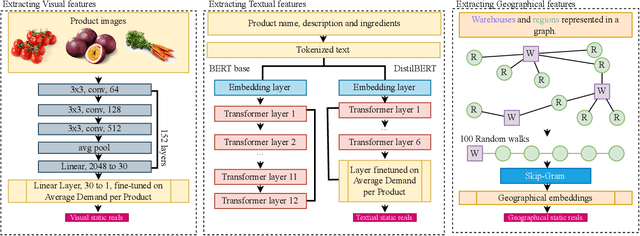
Multimodal demand forecasting aims at predicting product demand utilizing visual, textual, and contextual information. This paper proposes a method for multimodal product demand forecasting using convolutional, graph-based, and transformer-based architectures. Traditional approaches to demand forecasting rely on historical demand, product categories, and additional contextual information such as seasonality and events. However, these approaches have several shortcomings, such as the cold start problem making it difficult to predict product demand until sufficient historical data is available for a particular product, and their inability to properly deal with category dynamics. By incorporating multimodal information, such as product images and textual descriptions, our architecture aims to address the shortcomings of traditional approaches and outperform them. The experiments conducted on a large real-world dataset show that the proposed approach effectively predicts demand for a wide range of products. The multimodal pipeline presented in this work enhances the accuracy and reliability of the predictions, demonstrating the potential of leveraging multimodal information in product demand forecasting.
Multimodal Classification of Urban Micro-Events
Apr 30, 2019

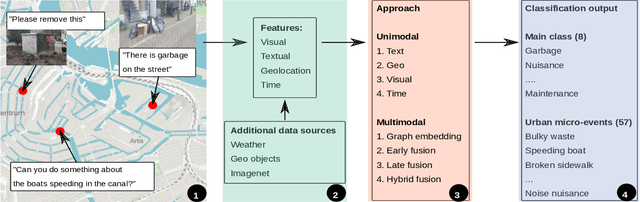
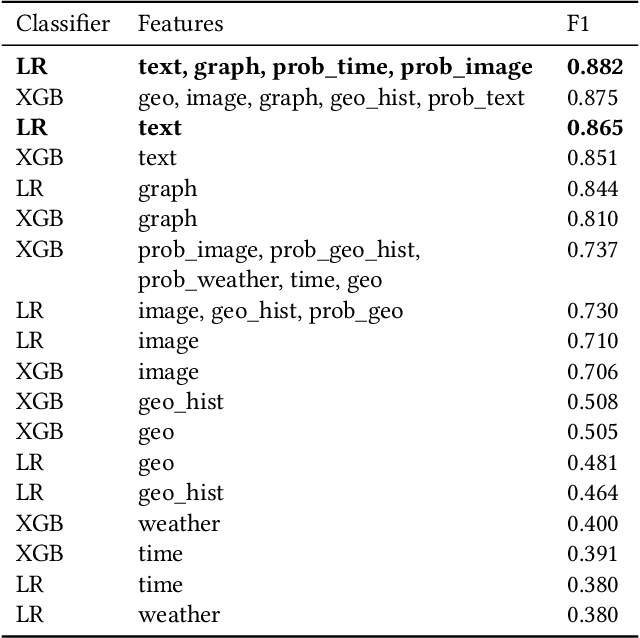
In this paper we seek methods to effectively detect urban micro-events. Urban micro-events are events which occur in cities, have limited geographical coverage and typically affect only a small group of citizens. Because of their scale these are difficult to identify in most data sources. However, by using citizen sensing to gather data, detecting them becomes feasible. The data gathered by citizen sensing is often multimodal and, as a consequence, the information required to detect urban micro-events is distributed over multiple modalities. This makes it essential to have a classifier capable of combining them. In this paper we explore several methods of creating such a classifier, including early, late, hybrid fusion and representation learning using multimodal graphs. We evaluate performance on a real world dataset obtained from a live citizen reporting system. We show that a multimodal approach yields higher performance than unimodal alternatives. Furthermore, we demonstrate that our hybrid combination of early and late fusion with multimodal embeddings performs best in classification of urban micro-events.