 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial Named Entity Recognition (MNER) for Knowledge-driven Materials Using Deep Learning Approach
Nov 04, 2022The scientific literature contains a wealth of cutting-edge knowledge in the field of materials science, as well as useful data (e.g., numerical data from experimental results, material properties and structure). These data are critical for data-driven machine learning (ML) and deep learning (DL) methods to accelerate material discovery. Due to the large and growing number of publications, it is difficult for humans to manually retrieve and retain this knowledge. In this context, we investigate a deep neural network model based on Bi-LSTM to retrieve knowledge from published scientific articles. The proposed deep neural network-based model achieves an f-1 score of \~97\% for the Material Named Entity Recognition (MNER) task. The study addresses motivation, relevant work, methodology, hyperparameters, and overall performance evaluation. The analysis provides insight into the results of the experiment and points to future directions for current research.
Distributed Ledger Technology based Integrated Healthcare Solution for Bangladesh
May 30, 2022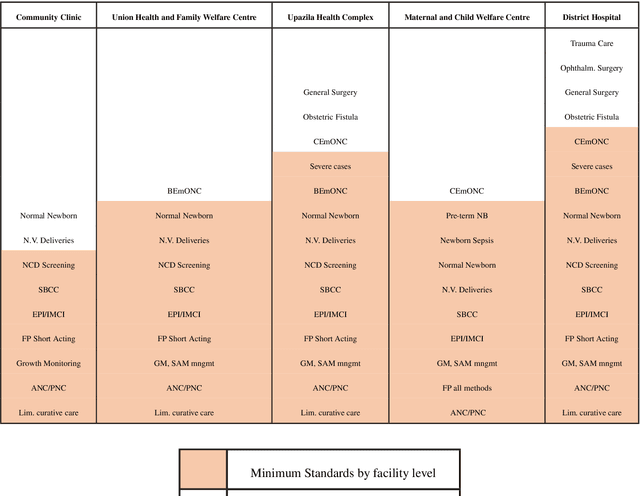
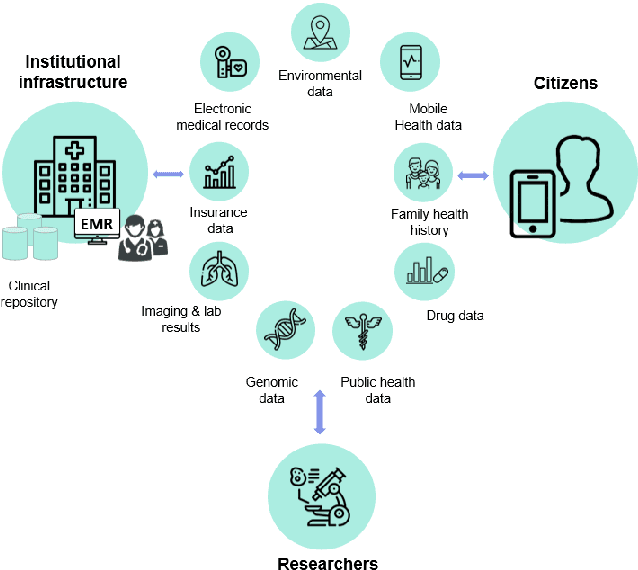
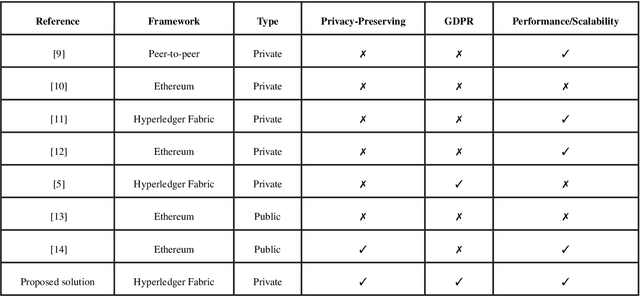
Healthcare data is sensitive and requires great protection. Encrypted electronic health records (EHRs) contain personal and sensitive data such as names and addresses. Having access to patient data benefits all of them. This paper proposes a blockchain-based distributed healthcare application platform for Bangladeshi public and private healthcare providers. Using data immutability and smart contracts, the suggested application framework allows users to create safe digital agreements for commerce or collaboration. Thus, all enterprises may securely collaborate using the same blockchain network, gaining data openness and read/write capacity. The proposed application consists of various application interfaces for various system users. For data integrity, privacy, permission and service availability, the proposed solution leverages Hyperledger fabric and Blockchain as a Service. Everyone will also have their own profile in the portal. A unique identity for each person and the installation of digital information centres across the country have greatly eased the process. It will collect systematic health data from each person which will be beneficial for research institutes and health-related organisations. A national data warehouse in Bangladesh is feasible for this application and It is also possible to keep a clean health sector by analysing data stored in this warehouse and conducting various purification algorithms using technologies like Data Science. Given that Bangladesh has both public and private health care, a straightforward digital strategy for all organisations is essential.
Study of keyword extraction techniques for Electric Double Layer Capacitor domain using text similarity indexes: An experimental analysis
Nov 13, 2021



Keywords perform a significant role in selecting various topic-related documents quite easily. Topics or keywords assigned by humans or experts provide accurate information. However, this practice is quite expensive in terms of resources and time management. Hence, it is more satisfying to utilize automated keyword extraction techniques. Nevertheless, before beginning the automated process, it is necessary to check and confirm how similar expert-provided and algorithm-generated keywords are. This paper presents an experimental analysis of similarity scores of keywords generated by different supervised and unsupervised automated keyword extraction algorithms with expert provided keywords from the Electric Double Layer Capacitor (EDLC) domain. The paper also analyses which texts provide better keywords like positive sentences or all sentences of the document. From the unsupervised algorithms, YAKE, TopicRank, MultipartiteRank, and KPMiner are employed for keyword extraction. From the supervised algorithms, KEA and WINGNUS are employed for keyword extraction. To assess the similarity of the extracted keywords with expert-provided keywords, Jaccard, Cosine, and Cosine with word vector similarity indexes are employed in this study. The experiment shows that the MultipartiteRank keyword extraction technique measured with cosine with word vector similarity index produces the best result with 92% similarity with expert provided keywords. This study can help the NLP researchers working with the EDLC domain or recommender systems to select more suitable keyword extraction and similarity index calculation techniques.