 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Short Term Energy Demand in Smart Grid: A Deep Learning Approach for Integrating Renewable Energy Sources in Line with SDGs 7, 9, and 13
Apr 14, 2023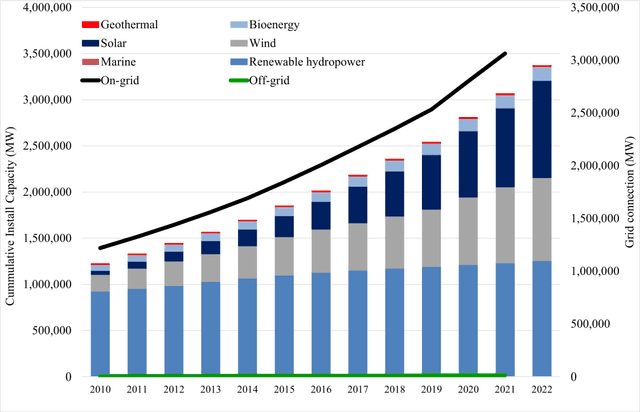
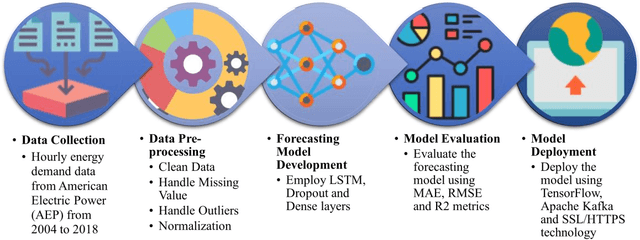
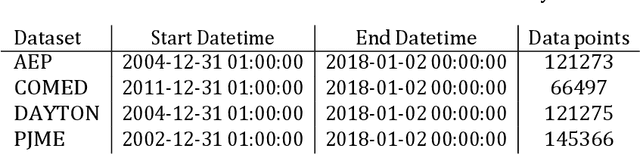
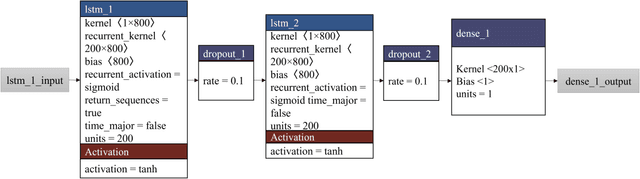
The integration of renewable energy sources into the power grid is becoming increasingly important as the world moves towards a more sustainable energy future in line with SDG 7. However, the intermittent nature of renewable energy sources can make it challenging to manage the power grid and ensure a stable supply of electricity, which is crucial for achieving SDG 9. In this paper, we propose a deep learning-based approach for predicting energy demand in a smart power grid, which can improve the integration of renewable energy sources by providing accurate predictions of energy demand. Our approach aligns with SDG 13 on climate action as it enables more efficient management of renewable energy resources. We use long short-term memory networks, which are well-suited for time series data, to capture complex patterns and dependencies in energy demand data. The proposed approach is evaluated using four datasets of historical short term energy demand data from different energy distribution companies including American Electric Power, Commonwealth Edison, Dayton Power and Light, and Pennsylvania-New Jersey-Maryland Interconnection. The proposed model is also compared with three other state of the art forecasting algorithms namely, Facebook Prophet, Support Vector Regressor, and Random Forest Regressor. The experimental results show that the proposed REDf model can accurately predict energy demand with a mean absolute error of 1.4%, indicating its potential to enhance the stability and efficiency of the power grid and contribute to achieving SDGs 7, 9, and 13. The proposed model also have the potential to manage the integration of renewable energy sources in an effective manner.
Material Named Entity Recognition (MNER) for Knowledge-driven Materials Using Deep Learning Approach
Nov 04, 2022The scientific literature contains a wealth of cutting-edge knowledge in the field of materials science, as well as useful data (e.g., numerical data from experimental results, material properties and structure). These data are critical for data-driven machine learning (ML) and deep learning (DL) methods to accelerate material discovery. Due to the large and growing number of publications, it is difficult for humans to manually retrieve and retain this knowledge. In this context, we investigate a deep neural network model based on Bi-LSTM to retrieve knowledge from published scientific articles. The proposed deep neural network-based model achieves an f-1 score of \~97\% for the Material Named Entity Recognition (MNER) task. The study addresses motivation, relevant work, methodology, hyperparameters, and overall performance evaluation. The analysis provides insight into the results of the experiment and points to future directions for current research.
Study of keyword extraction techniques for Electric Double Layer Capacitor domain using text similarity indexes: An experimental analysis
Nov 13, 2021



Keywords perform a significant role in selecting various topic-related documents quite easily. Topics or keywords assigned by humans or experts provide accurate information. However, this practice is quite expensive in terms of resources and time management. Hence, it is more satisfying to utilize automated keyword extraction techniques. Nevertheless, before beginning the automated process, it is necessary to check and confirm how similar expert-provided and algorithm-generated keywords are. This paper presents an experimental analysis of similarity scores of keywords generated by different supervised and unsupervised automated keyword extraction algorithms with expert provided keywords from the Electric Double Layer Capacitor (EDLC) domain. The paper also analyses which texts provide better keywords like positive sentences or all sentences of the document. From the unsupervised algorithms, YAKE, TopicRank, MultipartiteRank, and KPMiner are employed for keyword extraction. From the supervised algorithms, KEA and WINGNUS are employed for keyword extraction. To assess the similarity of the extracted keywords with expert-provided keywords, Jaccard, Cosine, and Cosine with word vector similarity indexes are employed in this study. The experiment shows that the MultipartiteRank keyword extraction technique measured with cosine with word vector similarity index produces the best result with 92% similarity with expert provided keywords. This study can help the NLP researchers working with the EDLC domain or recommender systems to select more suitable keyword extraction and similarity index calculation techniques.