 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Bayesian Uncertainty Quantification in Deep Probabilistic Image Segmentation
Nov 25, 2024Advancements in image segmentation play an integral role within the greater scope of Deep Learning-based computer vision. Furthermore, their widespread applicability in critical real-world tasks has given rise to challenges related to the reliability of such algorithms. Hence, uncertainty quantification has been extensively studied within this context, enabling expression of model ignorance (epistemic uncertainty) or data ambiguity (aleatoric uncertainty) to prevent uninformed decision making. Due to the rapid adoption of Convolutional Neural Network (CNN)-based segmentation models in high-stake applications, a substantial body of research has been published on this very topic, causing its swift expansion into a distinct field. This work provides a comprehensive overview of probabilistic segmentation by discussing fundamental concepts in uncertainty that govern advancements in the field as well as the application to various tasks. We identify that quantifying aleatoric and epistemic uncertainty approximates Bayesian inference w.r.t. to either latent variables or model parameters, respectively. Moreover, literature on both uncertainties trace back to four key applications; (1) to quantify statistical inconsistencies in the annotation process due ambiguous images, (2) correlating prediction error with uncertainty, (3) expanding the model hypothesis space for better generalization, and (4) active learning. Then, a discussion follows that includes an overview of utilized datasets for each of the applications and comparison of the available methods. We also highlight challenges related to architectures, uncertainty-based active learning, standardization and benchmarking, and recommendations for future work such as methods based on single forward passes and models that appropriately leverage volumetric data.
Improving Aleatoric Uncertainty Quantification in Multi-Annotated Medical Image Segmentation with Normalizing Flows
Aug 05, 2021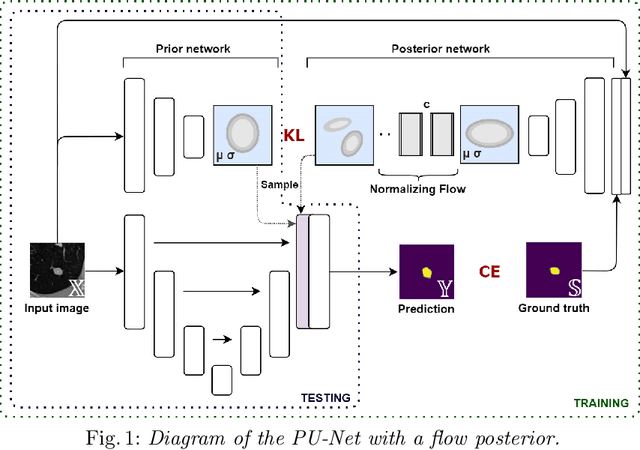

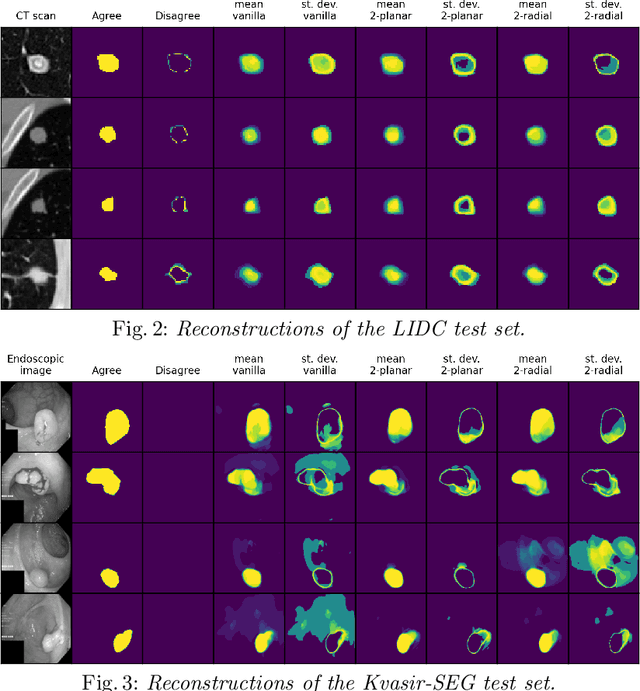
Quantifying uncertainty in medical image segmentation applications is essential, as it is often connected to vital decision-making. Compelling attempts have been made in quantifying the uncertainty in image segmentation architectures, e.g. to learn a density segmentation model conditioned on the input image. Typical work in this field restricts these learnt densities to be strictly Gaussian. In this paper, we propose to use a more flexible approach by introducing Normalizing Flows (NFs), which enables the learnt densities to be more complex and facilitate more accurate modeling for uncertainty. We prove this hypothesis by adopting the Probabilistic U-Net and augmenting the posterior density with an NF, allowing it to be more expressive. Our qualitative as well as quantitative (GED and IoU) evaluations on the multi-annotated and single-annotated LIDC-IDRI and Kvasir-SEG segmentation datasets, respectively, show a clear improvement. This is mostly apparent in the quantification of aleatoric uncertainty and the increased predictive performance of up to 14 percent. This result strongly indicates that a more flexible density model should be seriously considered in architectures that attempt to capture segmentation ambiguity through density modeling. The benefit of this improved modeling will increase human confidence in annotation and segmentation, and enable eager adoption of the technology in practice.
Out-of-Distribution Detection of Melanoma using Normalizing Flows
Mar 23, 2021

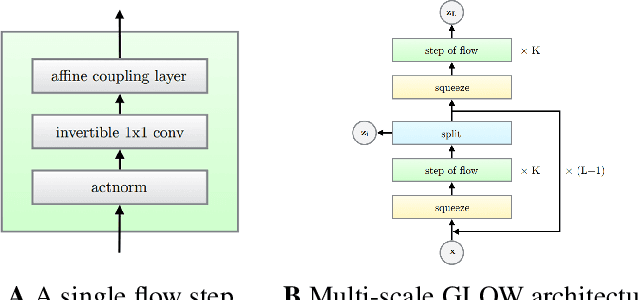
Generative modelling has been a topic at the forefront of machine learning research for a substantial amount of time. With the recent success in the field of machine learning, especially in deep learning, there has been an increased interest in explainable and interpretable machine learning. The ability to model distributions and provide insight in the density estimation and exact data likelihood is an example of such a feature. Normalizing Flows (NFs), a relatively new research field of generative modelling, has received substantial attention since it is able to do exactly this at a relatively low cost whilst enabling competitive generative results. While the generative abilities of NFs are typically explored, we focus on exploring the data distribution modelling for Out-of-Distribution (OOD) detection. Using one of the state-of-the-art NF models, GLOW, we attempt to detect OOD examples in the ISIC dataset. We notice that this model under performs in conform related research. To improve the OOD detection, we explore the masking methods to inhibit co-adaptation of the coupling layers however find no substantial improvement. Furthermore, we utilize Wavelet Flow which uses wavelets that can filter particular frequency components, thus simplifying the modeling process to data-driven conditional wavelet coefficients instead of complete images. This enables us to efficiently model larger resolution images in the hopes that it would capture more relevant features for OOD. The paper that introduced Wavelet Flow mainly focuses on its ability of sampling high resolution images and did not treat OOD detection. We present the results and propose several ideas for improvement such as controlling frequency components, using different wavelets and using other state-of-the-art NF architectures.