 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Capitalization and Punctuation for Automatic Speech Recognition Using Transformer and Chunk Merging
Aug 07, 2019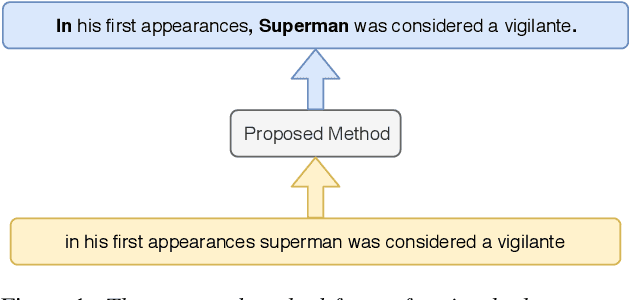
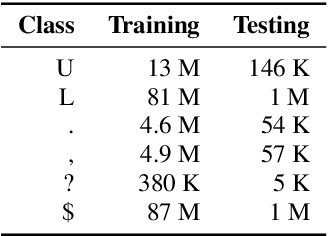
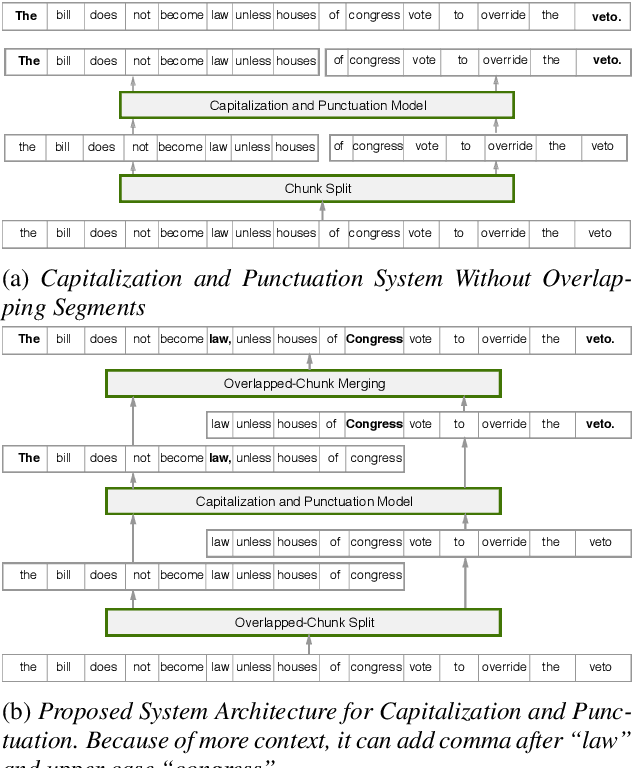
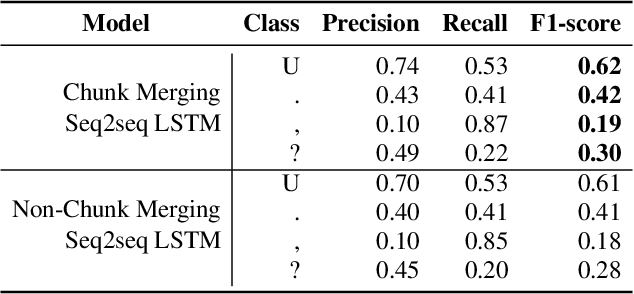
In recent years, studies on automatic speech recognition (ASR) have shown outstanding results that reach human parity on short speech segments. However, there are still difficulties in standardizing the output of ASR such as capitalization and punctuation restoration for long-speech transcription. The problems obstruct readers to understand the ASR output semantically and also cause difficulties for natural language processing models such as NER, POS and semantic parsing. In this paper, we propose a method to restore the punctuation and capitalization for long-speech ASR transcription. The method is based on Transformer models and chunk merging that allows us to (1), build a single model that performs punctuation and capitalization in one go, and (2), perform decoding in parallel while improving the prediction accuracy. Experiments on British National Corpus showed that the proposed approach outperforms existing methods in both accuracy and decoding speed.
A high quality and phonetic balanced speech corpus for Vietnamese
Apr 11, 2019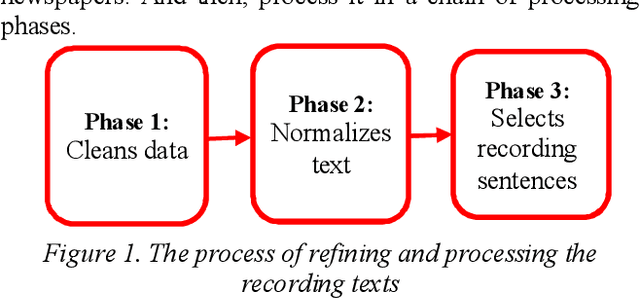
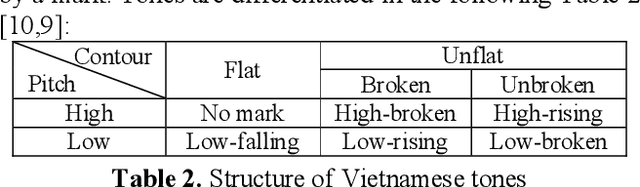

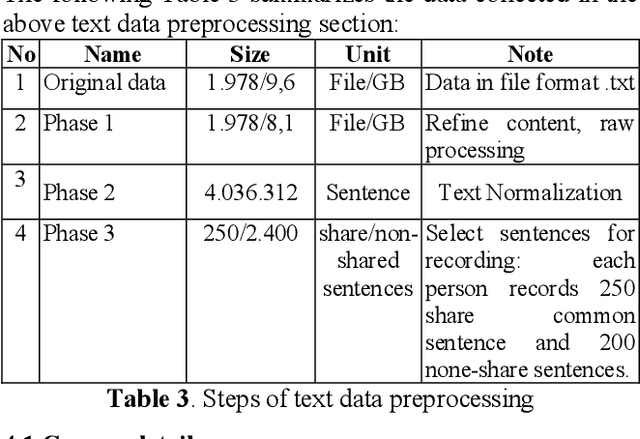
This paper presents a high quality Vietnamese speech corpus that can be used for analyzing Vietnamese speech characteristic as well as building speech synthesis models. The corpus consists of 5400 clean-speech utterances spoken by 12 speakers including 6 males and 6 females. The corpus is designed with phonetic balanced in mind so that it can be used for speech synthesis, especially, speech adaptation approaches. Specifically, all speakers utter a common dataset contains 250 phonetic balanced sentences. To increase the variety of speech context, each speaker also utters another 200 non-shared, phonetic-balanced sentences. The speakers are selected to cover a wide range of age and come from different regions of the North of Vietnam. The audios are recorded in a soundproof studio room, they are sampling at 48 kHz, 16 bits PCM, mono channel.
* 5 pages