 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHey That's Mine Imperceptible Watermarks are Preserved in Diffusion Generated Outputs
Aug 22, 2023Generative models have seen an explosion in popularity with the release of huge generative Diffusion models like Midjourney and Stable Diffusion to the public. Because of this new ease of access, questions surrounding the automated collection of data and issues regarding content ownership have started to build. In this paper we present new work which aims to provide ways of protecting content when shared to the public. We show that a generative Diffusion model trained on data that has been imperceptibly watermarked will generate new images with these watermarks present. We further show that if a given watermark is correlated with a certain feature of the training data, the generated images will also have this correlation. Using statistical tests we show that we are able to determine whether a model has been trained on marked data, and what data was marked. As a result our system offers a solution to protect intellectual property when sharing content online.
Long-Term Prediction of Natural Video Sequences with Robust Video Predictors
Aug 21, 2023



Predicting high dimensional video sequences is a curiously difficult problem. The number of possible futures for a given video sequence grows exponentially over time due to uncertainty. This is especially evident when trying to predict complicated natural video scenes from a limited snapshot of the world. The inherent uncertainty accumulates the further into the future you predict making long-term prediction very difficult. In this work we introduce a number of improvements to existing work that aid in creating Robust Video Predictors (RoViPs). We show that with a combination of deep Perceptual and uncertainty-based reconstruction losses we are able to create high quality short-term predictions. Attention-based skip connections are utilised to allow for long range spatial movement of input features to further improve performance. Finally, we show that by simply making the predictor robust to its own prediction errors, it is possible to produce very long, realistic natural video sequences using an iterated single-step prediction task.
OpenGAN: Open Set Generative Adversarial Networks
Mar 18, 2020
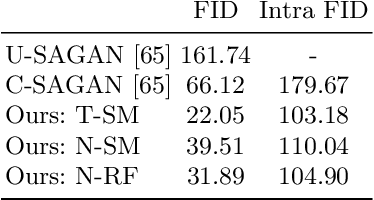

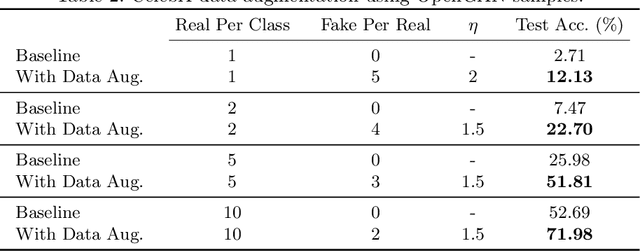
Many existing conditional Generative Adversarial Networks (cGANs) are limited to conditioning on pre-defined and fixed class-level semantic labels or attributes. We propose an open set GAN architecture (OpenGAN) that is conditioned per-input sample with a feature embedding drawn from a metric space. Using a state-of-the-art metric learning model that encodes both class-level and fine-grained semantic information, we are able to generate samples that are semantically similar to a given source image. The semantic information extracted by the metric learning model transfers to out-of-distribution novel classes, allowing the generative model to produce samples that are outside of the training distribution. We show that our proposed method is able to generate 256$\times$256 resolution images from novel classes that are of similar visual quality to those from the training classes. In lieu of a source image, we demonstrate that random sampling of the metric space also results in high-quality samples. We show that interpolation in the feature space and latent space results in semantically and visually plausible transformations in the image space. Finally, the usefulness of the generated samples to the downstream task of data augmentation is demonstrated. We show that classifier performance can be significantly improved by augmenting the training data with OpenGAN samples on classes that are outside of the GAN training distribution.
Embracing Contact: Pushing Multiple Objects with Robot's Forearm
Jun 17, 2019

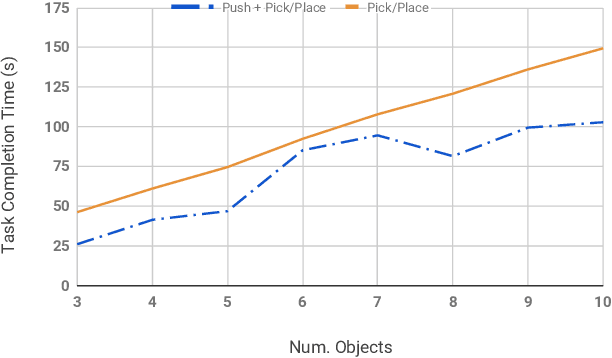
Grasping is the dominant approach for robot manipulation, but only a single object can be grasped at a time. Nonprehensile manipulation offers richer set of interactions, however state-of-the-art is limited to using the end-effector only. We propose using a robot link (forearm) to push multiple objects at once. In a simulated task where the robot's task is to sort two kinds of objects into their respective goal regions, we show that a greedy strategy that uses a combination of forearm pushes and pick and place operations reduces task completion time by %28 compared to picking and placing each object individually.