 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-efficient Reinforcement Learning in Robotic Table Tennis
Nov 11, 2020

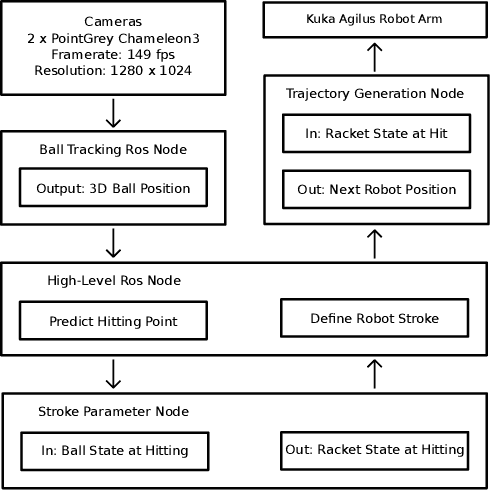
Reinforcement learning (RL) has recently shown impressive success in various computer games and simulations. Most of these successes are based on numerous episodes to be learned from. For typical robotic applications, however, the number of feasible attempts is very limited. In this paper we present a sample-efficient RL algorithm applied to the example of a table tennis robot. In table tennis every stroke is different, of varying placement, speed and spin. Therefore, an accurate return has be found depending on a high-dimensional continuous state space. To make learning in few trials possible the method is embedded into our robot system. In this way we can use a one-step environment. The state space depends on the ball at hitting time (position, velocity, spin) and the action is the racket state (orientation, velocity) at hitting. An actor-critic based deterministic policy gradient algorithm was developed for accelerated learning. Our approach shows competitive performance in both simulation and on the real robot in different challenging scenarios. Accurate results are always obtained within under 200 episodes of training. The video presenting our experiments is available at https://youtu.be/uRAtdoL6Wpw.