 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Interpretable Nonlinear Modeling for Multiple Time Series
Sep 29, 2023Predictive linear and nonlinear models based on kernel machines or deep neural networks have been used to discover dependencies among time series. This paper proposes an efficient nonlinear modeling approach for multiple time series, with a complexity comparable to linear vector autoregressive (VAR) models while still incorporating nonlinear interactions among different time-series variables. The modeling assumption is that the set of time series is generated in two steps: first, a linear VAR process in a latent space, and second, a set of invertible and Lipschitz continuous nonlinear mappings that are applied per sensor, that is, a component-wise mapping from each latent variable to a variable in the measurement space. The VAR coefficient identification provides a topology representation of the dependencies among the aforementioned variables. The proposed approach models each component-wise nonlinearity using an invertible neural network and imposes sparsity on the VAR coefficients to reflect the parsimonious dependencies usually found in real applications. To efficiently solve the formulated optimization problems, a custom algorithm is devised combining proximal gradient descent, stochastic primal-dual updates, and projection to enforce the corresponding constraints. Experimental results on both synthetic and real data sets show that the proposed algorithm improves the identification of the support of the VAR coefficients in a parsimonious manner while also improving the time-series prediction, as compared to the current state-of-the-art methods.
Explainable nonlinear modelling of multiple time series with invertible neural networks
Jul 01, 2021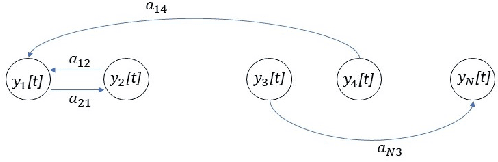

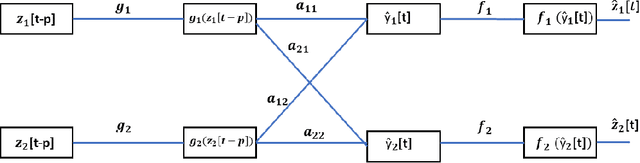
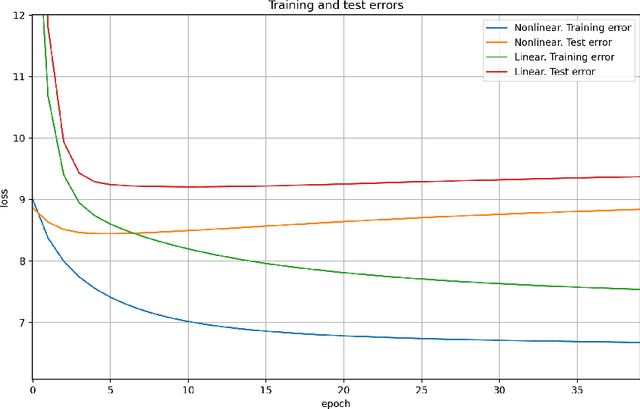
A method for nonlinear topology identification is proposed, based on the assumption that a collection of time series are generated in two steps: i) a vector autoregressive process in a latent space, and ii) a nonlinear, component-wise, monotonically increasing observation mapping. The latter mappings are assumed invertible, and are modelled as shallow neural networks, so that their inverse can be numerically evaluated, and their parameters can be learned using a technique inspired in deep learning. Due to the function inversion, the back-propagation step is not straightforward, and this paper explains the steps needed to calculate the gradients applying implicit differentiation. Whereas the model explainability is the same as that for linear VAR processes, preliminary numerical tests show that the prediction error becomes smaller.
Online Hyperparameter Search Interleaved with Proximal Parameter Updates
Apr 06, 2020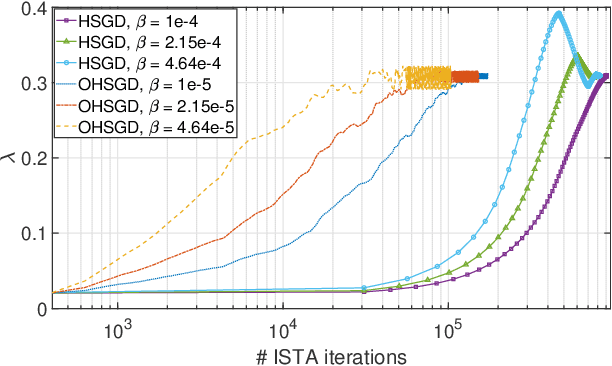
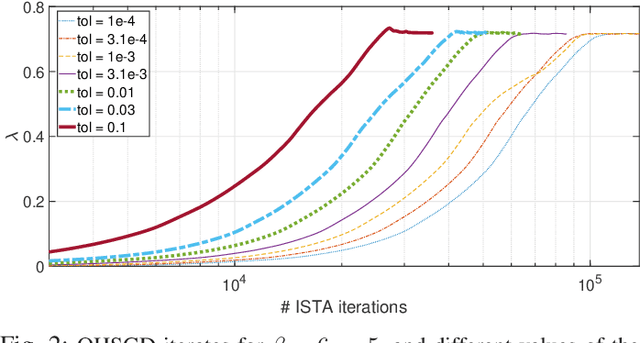
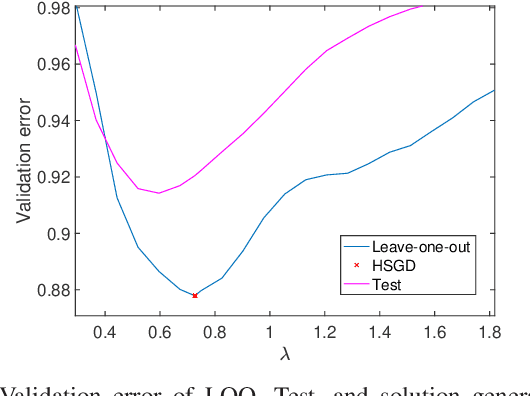
There is a clear need for efficient algorithms to tune hyperparameters for statistical learning schemes, since the commonly applied search methods (such as grid search with N-fold cross-validation) are inefficient and/or approximate. Previously existing algorithms that efficiently search for hyperparameters relying on the smoothness of the cost function cannot be applied in problems such as Lasso regression. In this contribution, we develop a hyperparameter optimization method that relies on the structure of proximal gradient methods and does not require a smooth cost function. Such a method is applied to Leave-one-out (LOO)-validated Lasso and Group Lasso to yield efficient, data-driven, hyperparameter optimization algorithms. Numerical experiments corroborate the convergence of the proposed method to a local optimum of the LOO validation error curve, and the efficiency of its approximations.