 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting IR Personalization Performance using Pre-retrieval Query Predictors
Jan 24, 2024Personalization generally improves the performance of queries but in a few cases it may also harms it. If we are able to predict and therefore to disable personalization for those situations, the overall performance will be higher and users will be more satisfied with personalized systems. We use some state-of-the-art pre-retrieval query performance predictors and propose some others including the user profile information for the previous purpose. We study the correlations among these predictors and the difference between the personalized and the original queries. We also use classification and regression techniques to improve the results and finally reach a bit more than one third of the maximum ideal performance. We think this is a good starting point within this research line, which certainly needs more effort and improvements.
Publication venue recommendation using profiles based on clustering
Jan 19, 2024
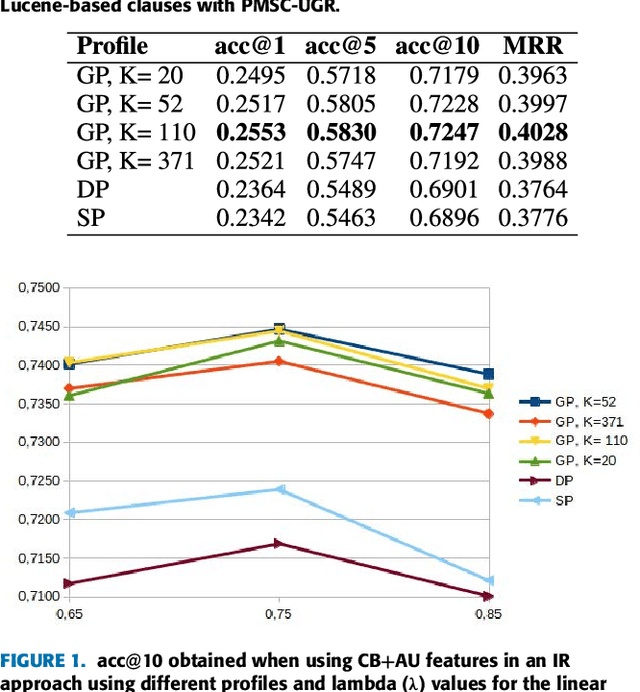


In this paper we study the venue recommendation problem in order to help researchers to identify a journal or conference to submit a given paper. A common approach to tackle this problem is to build profiles defining the scope of each venue. Then, these profiles are compared against the target paper. In our approach we will study how clustering techniques can be used to construct topic-based profiles and use an Information Retrieval based approach to obtain the final recommendations. Additionally, we will explore how the use of authorship, representing a complementary piece of information, helps to improve the recommendations.
Use of topical and temporal profiles and their hybridisation for content-based recommendation
Jan 19, 2024In the context of content-based recommender systems, the aim of this paper is to determine how better profiles can be built and how these affect the recommendation process based on the incorporation of temporality, i.e. the inclusion of time in the recommendation process, and topicality, i.e. the representation of texts associated with users and items using topics and their combination. The main contribution of the paper is to present two different ways of hybridising these two dimensions and to evaluate and compare them with other alternatives.
On the selection of the correct number of terms for profile construction: theoretical and empirical analysis
Jan 19, 2024



In this paper, we examine the problem of building a user profile from a set of documents. This profile will consist of a subset of the most representative terms in the documents that best represent user preferences or interests. Inspired by the discrete concentration theory we have conducted an axiomatic study of seven properties that a selection function should fulfill: the minimum and maximum uncertainty principle, invariant to adding zeros, invariant to scale transformations, principle of nominal increase, transfer principle and the richest get richer inequality. We also present a novel selection function based on the use of similarity metrics, and more specifically the cosine measure which is commonly used in information retrieval, and demonstrate that this verifies six of the properties in addition to a weaker variant of the transfer principle, thereby representing a good selection approach. The theoretical study was complemented with an empirical study to compare the performance of different selection criteria (weight- and unweight-based) using real data in a parliamentary setting. In this study, we analyze the performance of the different functions focusing on the two main factors affecting the selection process: profile size (number of terms) and weight distribution. These profiles are then used in a document filtering task to show that our similarity-based approach performs well in terms not only of recommendation accuracy but also efficiency (we obtain smaller profiles and consequently faster recommendations).
Automatic Construction of Multi-faceted User Profiles using Text Clustering and its Application to Expert Recommendation and Filtering Problems
Jan 19, 2024



In the information age we are living in today, not only are we interested in accessing multimedia objects such as documents, videos, etc. but also in searching for professional experts, people or celebrities, possibly for professional needs or just for fun. Information access systems need to be able to extract and exploit various sources of information (usually in text format) about such individuals, and to represent them in a suitable way usually in the form of a profile. In this article, we tackle the problems of profile-based expert recommendation and document filtering from a machine learning perspective by clustering expert textual sources to build profiles and capture the different hidden topics in which the experts are interested. The experts will then be represented by means of multi-faceted profiles. Our experiments show that this is a valid technique to improve the performance of expert finding and document filtering.
LDA-based Term Profiles for Expert Finding in a Political Setting
Jan 19, 2024A common task in many political institutions (i.e. Parliament) is to find politicians who are experts in a particular field. In order to tackle this problem, the first step is to obtain politician profiles which include their interests, and these can be automatically learned from their speeches. As a politician may have various areas of expertise, one alternative is to use a set of subprofiles, each of which covers a different subject. In this study, we propose a novel approach for this task by using latent Dirichlet allocation (LDA) to determine the main underlying topics of each political speech, and to distribute the related terms among the different topic-based subprofiles. With this objective, we propose the use of fifteen distance and similarity measures to automatically determine the optimal number of topics discussed in a document, and to demonstrate that every measure converges into five strategies: Euclidean, Dice, Sorensen, Cosine and Overlap. Our experimental results showed that the scores of the different accuracy metrics of the proposed strategies tended to be higher than those of the baselines for expert recommendation tasks, and that the use of an appropriate number of topics has proved relevant.
Partially Specified Belief Functions
Mar 06, 2013This paper presents a procedure to determine a complete belief function from the known values of belief for some of the subsets of the frame of discerment. The method is based on the principle of minimum commitment and a new principle called the focusing principle. This additional principle is based on the idea that belief is specified for the most relevant sets: the focal elements. The resulting procedure is compared with existing methods of building complete belief functions: the minimum specificity principle and the least commitment principle.
A probabilistic methodology for multilabel classification
Feb 28, 2013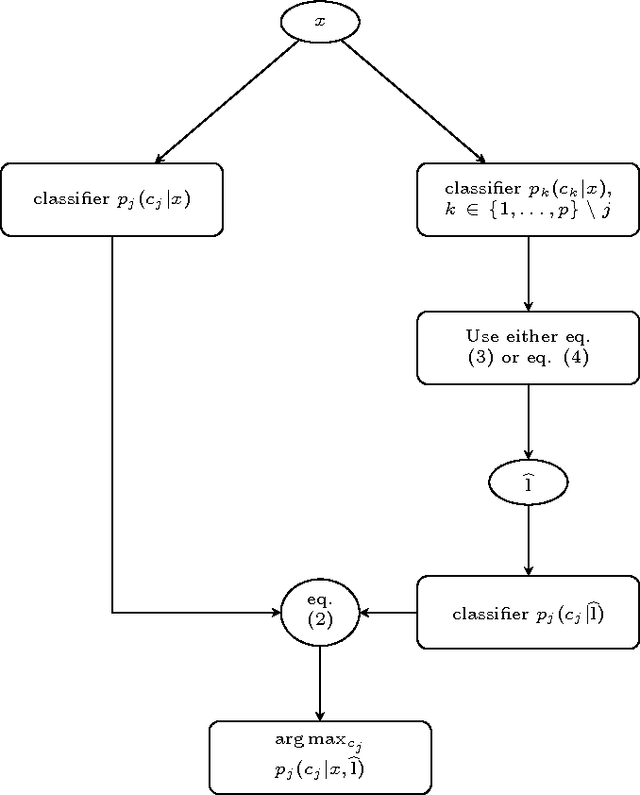



Multilabel classification is a relatively recent subfield of machine learning. Unlike to the classical approach, where instances are labeled with only one category, in multilabel classification, an arbitrary number of categories is chosen to label an instance. Due to the problem complexity (the solution is one among an exponential number of alternatives), a very common solution (the binary method) is frequently used, learning a binary classifier for every category, and combining them all afterwards. The assumption taken in this solution is not realistic, and in this work we give examples where the decisions for all the labels are not taken independently, and thus, a supervised approach should learn those existing relationships among categories to make a better classification. Therefore, we show here a generic methodology that can improve the results obtained by a set of independent probabilistic binary classifiers, by using a combination procedure with a classifier trained on the co-occurrences of the labels. We show an exhaustive experimentation in three different standard corpora of labeled documents (Reuters-21578, Ohsumed-23 and RCV1), which present noticeable improvements in all of them, when using our methodology, in three probabilistic base classifiers.
Independence Concepts for Convex Sets of Probabilities
Feb 20, 2013In this paper we study different concepts of independence for convex sets of probabilities. There will be two basic ideas for independence. The first is irrelevance. Two variables are independent when a change on the knowledge about one variable does not affect the other. The second one is factorization. Two variables are independent when the joint convex set of probabilities can be decomposed on the product of marginal convex sets. In the case of the Theory of Probability, these two starting points give rise to the same definition. In the case of convex sets of probabilities, the resulting concepts will be strongly related, but they will not be equivalent. As application of the concept of independence, we shall consider the problem of building a global convex set from marginal convex sets of probabilities.
An Algorithm for Finding Minimum d-Separating Sets in Belief Networks
Feb 13, 2013



The criterion commonly used in directed acyclic graphs (dags) for testing graphical independence is the well-known d-separation criterion. It allows us to build graphical representations of dependency models (usually probabilistic dependency models) in the form of belief networks, which make easy interpretation and management of independence relationships possible, without reference to numerical parameters (conditional probabilities). In this paper, we study the following combinatorial problem: finding the minimum d-separating set for two nodes in a dag. This set would represent the minimum information (in the sense of minimum number of variables) necessary to prevent these two nodes from influencing each other. The solution to this basic problem and some of its extensions can be useful in several ways, as we shall see later. Our solution is based on a two-step process: first, we reduce the original problem to the simpler one of finding a minimum separating set in an undirected graph, and second, we develop an algorithm for solving it.