 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA probabilistic methodology for multilabel classification
Paper and Code
Feb 28, 2013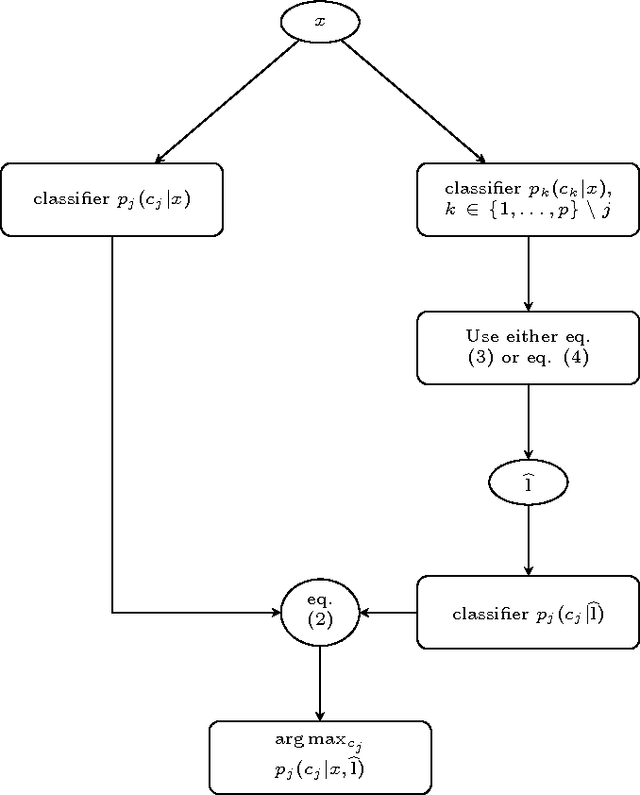



Multilabel classification is a relatively recent subfield of machine learning. Unlike to the classical approach, where instances are labeled with only one category, in multilabel classification, an arbitrary number of categories is chosen to label an instance. Due to the problem complexity (the solution is one among an exponential number of alternatives), a very common solution (the binary method) is frequently used, learning a binary classifier for every category, and combining them all afterwards. The assumption taken in this solution is not realistic, and in this work we give examples where the decisions for all the labels are not taken independently, and thus, a supervised approach should learn those existing relationships among categories to make a better classification. Therefore, we show here a generic methodology that can improve the results obtained by a set of independent probabilistic binary classifiers, by using a combination procedure with a classifier trained on the co-occurrences of the labels. We show an exhaustive experimentation in three different standard corpora of labeled documents (Reuters-21578, Ohsumed-23 and RCV1), which present noticeable improvements in all of them, when using our methodology, in three probabilistic base classifiers.