 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to reconstruct signals with inexact sensing operator via knowledge distillation
Jan 18, 2025



In computational optical imaging and wireless communications, signals are acquired through linear coded and noisy projections, which are recovered through computational algorithms. Deep model-based approaches, i.e., neural networks incorporating the sensing operators, are the state-of-the-art for signal recovery. However, these methods require exact knowledge of the sensing operator, which is often unavailable in practice, leading to performance degradation. Consequently, we propose a new recovery paradigm based on knowledge distillation. A teacher model, trained with full or almost exact knowledge of a synthetic sensing operator, guides a student model with an inexact real sensing operator. The teacher is interpreted as a relaxation of the student since it solves a problem with fewer constraints, which can guide the student to achieve higher performance. We demonstrate the improvement of signal reconstruction in computational optical imaging for single-pixel imaging with miscalibrated coded apertures systems and multiple-input multiple-output symbols detection with inexact channel matrix.
Learning Point Spread Function Invertibility Assessment for Image Deconvolution
May 25, 2024Deep-learning (DL)-based image deconvolution (ID) has exhibited remarkable recovery performance, surpassing traditional linear methods. However, unlike traditional ID approaches that rely on analytical properties of the point spread function (PSF) to achieve high recovery performance - such as specific spectrum properties or small conditional numbers in the convolution matrix - DL techniques lack quantifiable metrics for evaluating PSF suitability for DL-assisted recovery. Aiming to enhance deconvolution quality, we propose a metric that employs a non-linear approach to learn the invertibility of an arbitrary PSF using a neural network by mapping it to a unit impulse. A lower discrepancy between the mapped PSF and a unit impulse indicates a higher likelihood of successful inversion by a DL network. Our findings reveal that this metric correlates with high recovery performance in DL and traditional methods, thereby serving as an effective regularizer in deconvolution tasks. This approach reduces the computational complexity over conventional condition number assessments and is a differentiable process. These useful properties allow its application in designing diffractive optical elements through end-to-end (E2E) optimization, achieving invertible PSFs, and outperforming the E2E baseline framework.
Building Robust Deep Neural Networks for Road Sign Detection
Dec 26, 2017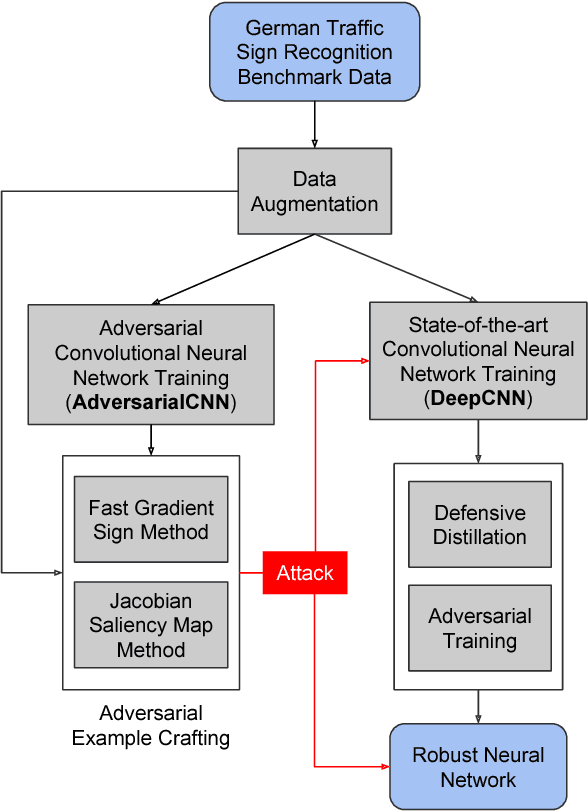
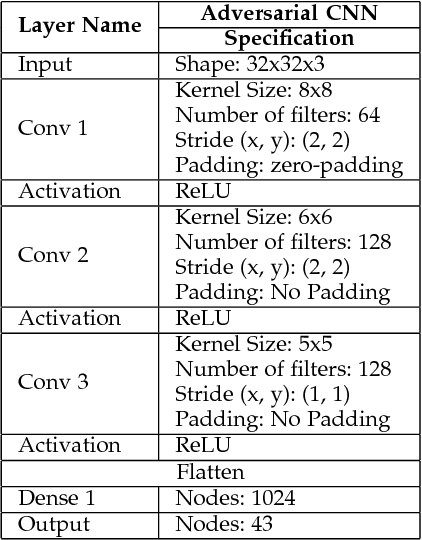
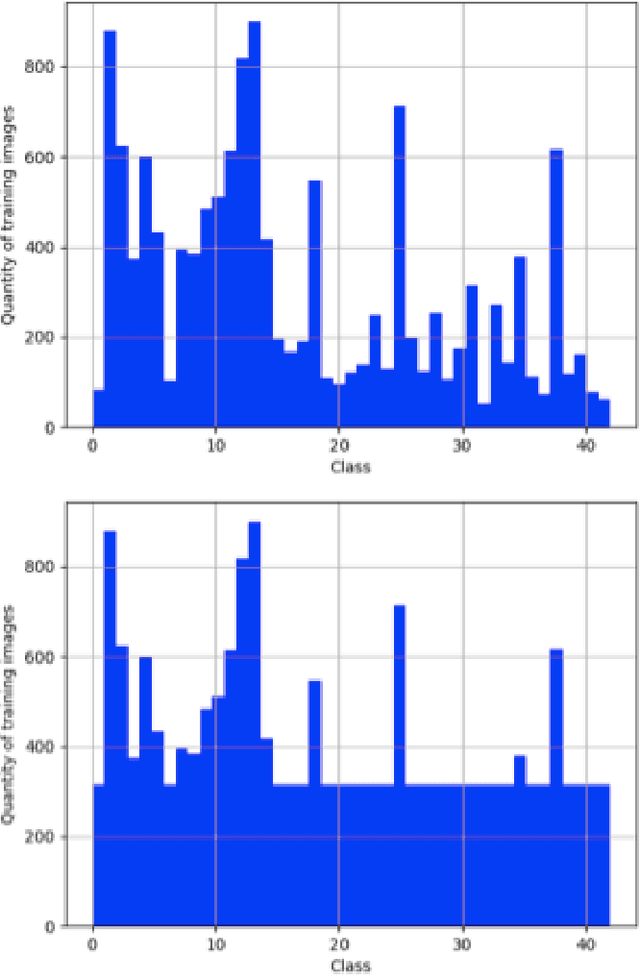
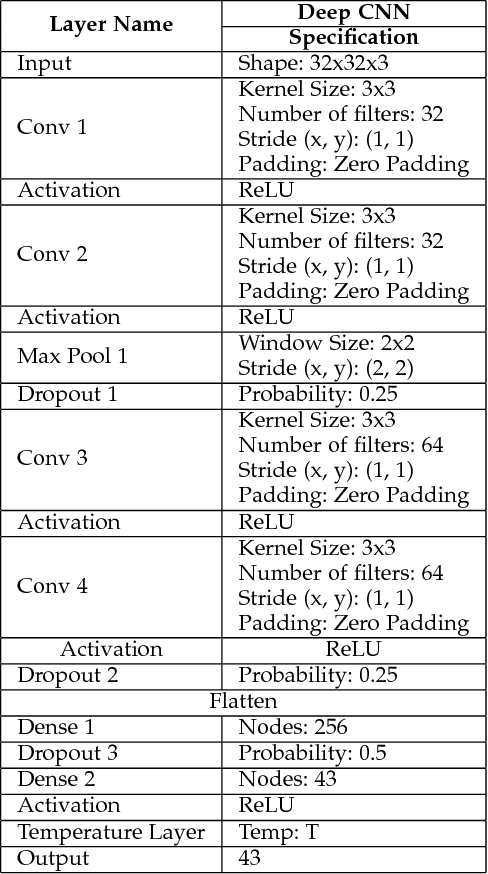
Deep Neural Networks are built to generalize outside of training set in mind by using techniques such as regularization, early stopping and dropout. But considerations to make them more resilient to adversarial examples are rarely taken. As deep neural networks become more prevalent in mission-critical and real-time systems, miscreants start to attack them by intentionally making deep neural networks to misclassify an object of one type to be seen as another type. This can be catastrophic in some scenarios where the classification of a deep neural network can lead to a fatal decision by a machine. In this work, we used GTSRB dataset to craft adversarial samples by Fast Gradient Sign Method and Jacobian Saliency Method, used those crafted adversarial samples to attack another Deep Convolutional Neural Network and built the attacked network to be more resilient against adversarial attacks by making it more robust by Defensive Distillation and Adversarial Training