 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models, Benchmark and Efficient Evaluation
Feb 02, 2022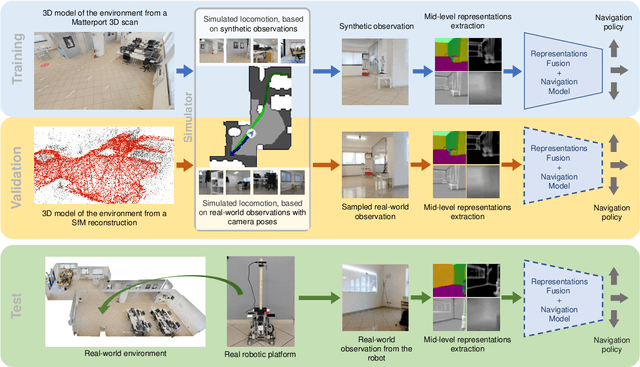
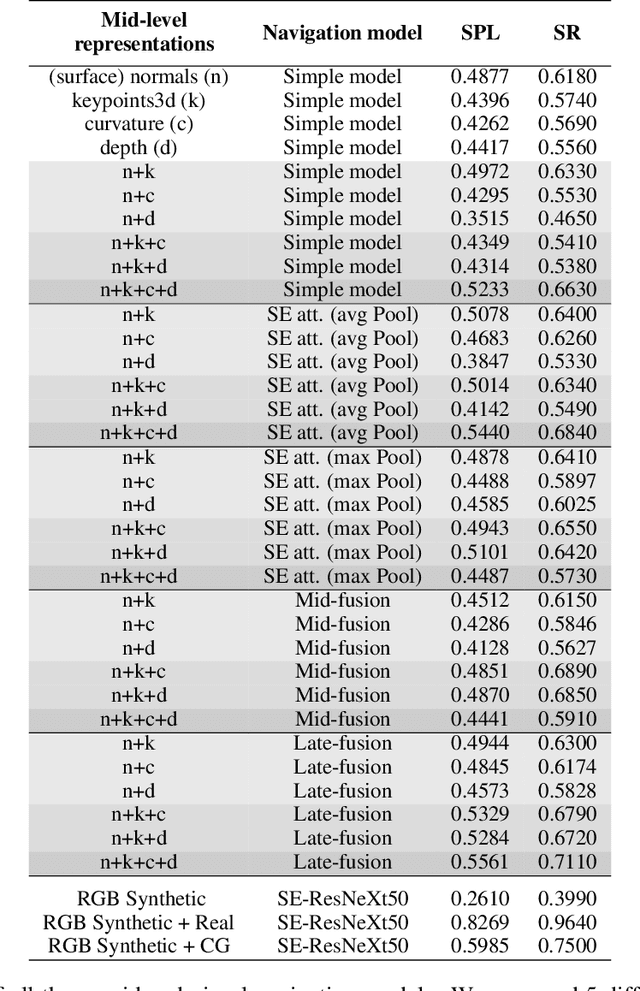


Navigating complex indoor environments requires a deep understanding of the space the robotic agent is acting into to correctly inform the navigation process of the agent towards the goal location. In recent learning-based navigation approaches, the scene understanding and navigation abilities of the agent are achieved simultaneously by collecting the required experience in simulation. Unfortunately, even if simulators represent an efficient tool to train navigation policies, the resulting models often fail when transferred into the real world. One possible solution is to provide the navigation model with mid-level visual representations containing important domain-invariant properties of the scene. But, what are the best representations that facilitate the transfer of a model to the real-world? How can they be combined? In this work we address these issues by proposing a benchmark of Deep Learning architectures to combine a range of mid-level visual representations, to perform a PointGoal navigation task following a Reinforcement Learning setup. All the proposed navigation models have been trained with the Habitat simulator on a synthetic office environment and have been tested on the same real-world environment using a real robotic platform. To efficiently assess their performance in a real context, a validation tool has been proposed to generate realistic navigation episodes inside the simulator. Our experiments showed that navigation models can benefit from the multi-modal input and that our validation tool can provide good estimation of the expected navigation performance in the real world, while saving time and resources. The acquired synthetic and real 3D models of the environment, together with the code of our validation tool built on top of Habitat, are publicly available at the following link: https://iplab.dmi.unict.it/EmbodiedVN/
On Embodied Visual Navigation in Real Environments Through Habitat
Oct 26, 2020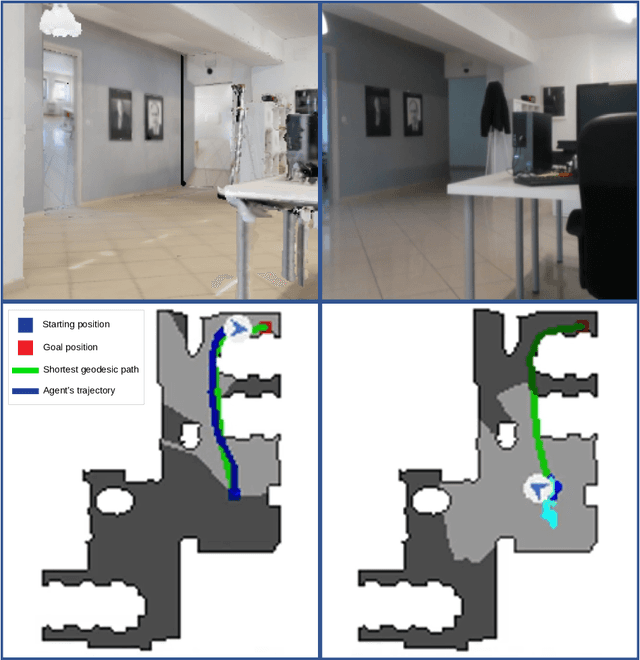
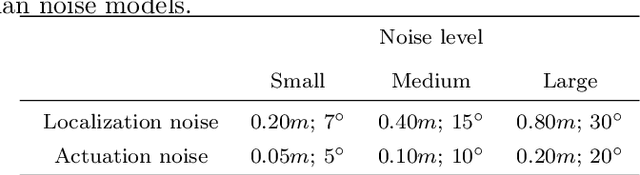
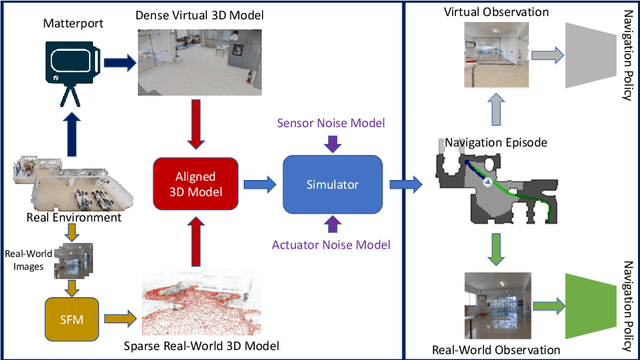
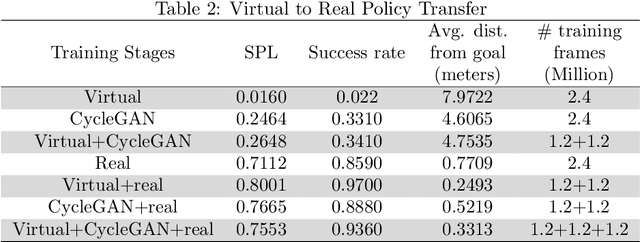
Visual navigation models based on deep learning can learn effective policies when trained on large amounts of visual observations through reinforcement learning. Unfortunately, collecting the required experience in the real world requires the deployment of a robotic platform, which is expensive and time-consuming. To deal with this limitation, several simulation platforms have been proposed in order to train visual navigation policies on virtual environments efficiently. Despite the advantages they offer, simulators present a limited realism in terms of appearance and physical dynamics, leading to navigation policies that do not generalize in the real world. In this paper, we propose a tool based on the Habitat simulator which exploits real world images of the environment, together with sensor and actuator noise models, to produce more realistic navigation episodes. We perform a range of experiments to assess the ability of such policies to generalize using virtual and real-world images, as well as observations transformed with unsupervised domain adaptation approaches. We also assess the impact of sensor and actuation noise on the navigation performance and investigate whether it allows to learn more robust navigation policies. We show that our tool can effectively help to train and evaluate navigation policies on real-world observations without running navigation pisodes in the real world.