 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing k4.0s: a Model for Mixed-Criticality Container Orchestration in Industry 4.0
May 27, 2022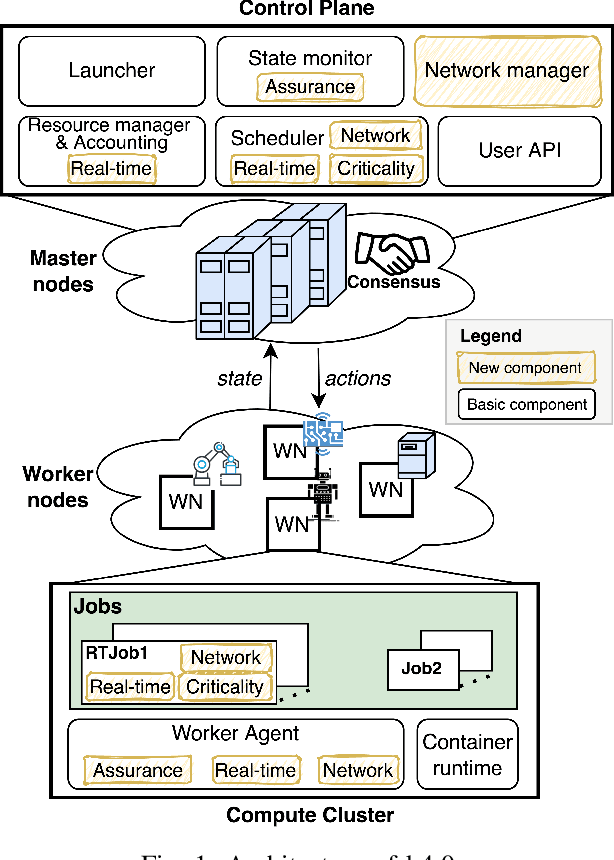
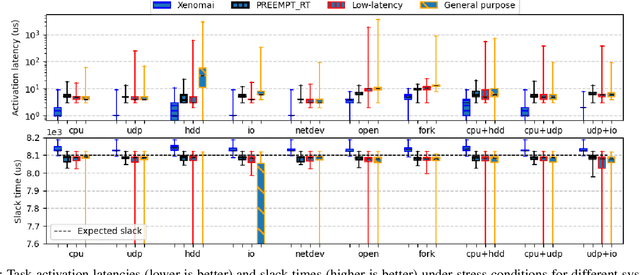
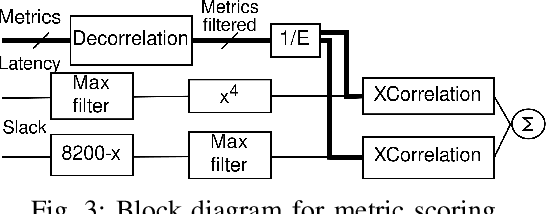
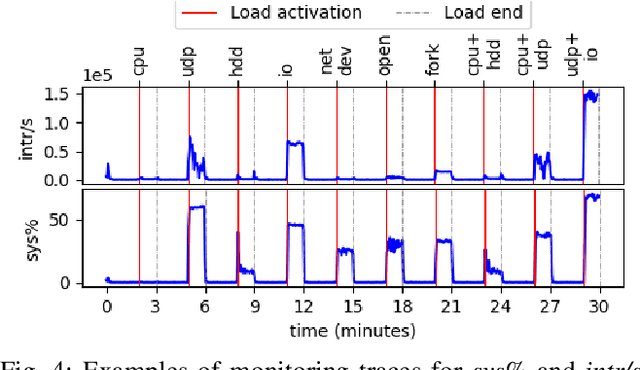
Time predictable edge cloud is seen as the answer for many arising needs in Industry 4.0 environments, since it is able to provide flexible, modular, and reconfigurable services with low latency and reduced costs. Orchestration systems are becoming the core component of clouds since they take decisions on the placement and lifecycle of software components. Current solutions start introducing real-time containers support for time predictability; however, these approaches lack of determinism as well as support for workloads requiring multiple levels of assurance/criticality. In this paper, we present k4.0s, an orchestration model for real-time and mixed-criticality environments, which includes timeliness, criticality and network requirements. The model leverages new abstractions for both node and jobs, e.g., node assurance, and requires novel monitoring strategies. We sketch an implementation of the proposal based on Kubernetes, and present an experimentation motivating the need for node assurance levels and adequate monitoring.
Enhancing the Analysis of Software Failures in Cloud Computing Systems with Deep Learning
Jun 29, 2021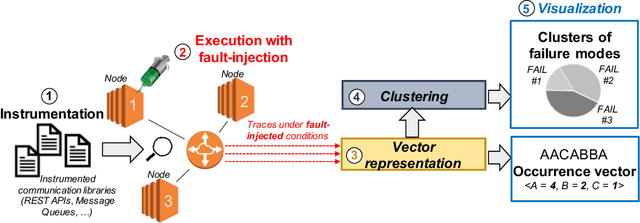

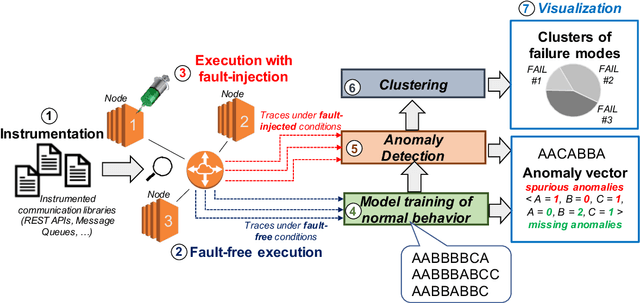
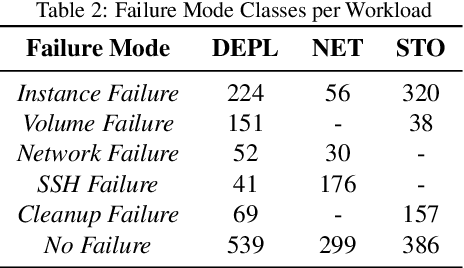
Identifying the failure modes of cloud computing systems is a difficult and time-consuming task, due to the growing complexity of such systems, and the large volume and noisiness of failure data. This paper presents a novel approach for analyzing failure data from cloud systems, in order to relieve human analysts from manually fine-tuning the data for feature engineering. The approach leverages Deep Embedded Clustering (DEC), a family of unsupervised clustering algorithms based on deep learning, which uses an autoencoder to optimize data dimensionality and inter-cluster variance. We applied the approach in the context of the OpenStack cloud computing platform, both on the raw failure data and in combination with an anomaly detection pre-processing algorithm. The results show that the performance of the proposed approach, in terms of purity of clusters, is comparable to, or in some cases even better than manually fine-tuned clustering, thus avoiding the need for deep domain knowledge and reducing the effort to perform the analysis. In all cases, the proposed approach provides better performance than unsupervised clustering when no feature engineering is applied to the data. Moreover, the distribution of failure modes from the proposed approach is closer to the actual frequency of the failure modes.