 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Analysis of Software Failures in Cloud Computing Systems with Deep Learning
Paper and Code
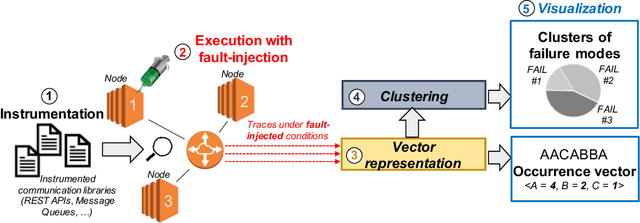

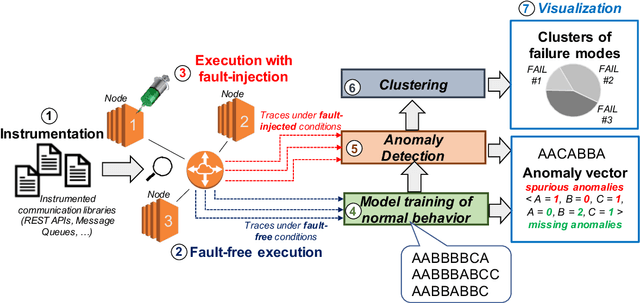
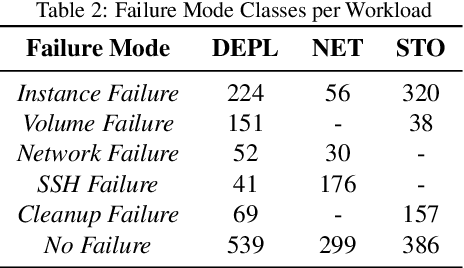
Identifying the failure modes of cloud computing systems is a difficult and time-consuming task, due to the growing complexity of such systems, and the large volume and noisiness of failure data. This paper presents a novel approach for analyzing failure data from cloud systems, in order to relieve human analysts from manually fine-tuning the data for feature engineering. The approach leverages Deep Embedded Clustering (DEC), a family of unsupervised clustering algorithms based on deep learning, which uses an autoencoder to optimize data dimensionality and inter-cluster variance. We applied the approach in the context of the OpenStack cloud computing platform, both on the raw failure data and in combination with an anomaly detection pre-processing algorithm. The results show that the performance of the proposed approach, in terms of purity of clusters, is comparable to, or in some cases even better than manually fine-tuned clustering, thus avoiding the need for deep domain knowledge and reducing the effort to perform the analysis. In all cases, the proposed approach provides better performance than unsupervised clustering when no feature engineering is applied to the data. Moreover, the distribution of failure modes from the proposed approach is closer to the actual frequency of the failure modes.