 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistantly-Supervised Neural Relation Extraction with Side Information using BERT
May 10, 2020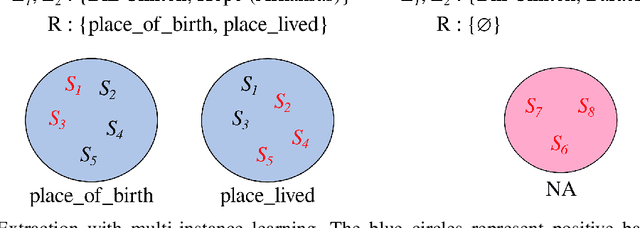
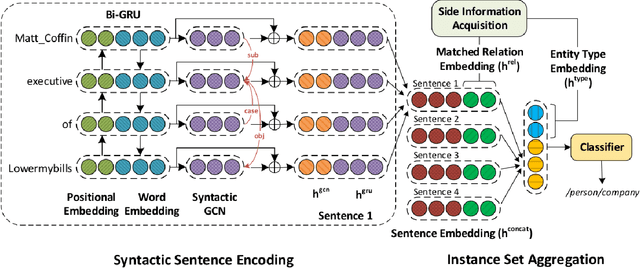
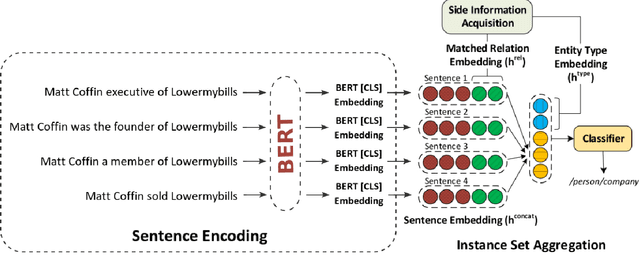
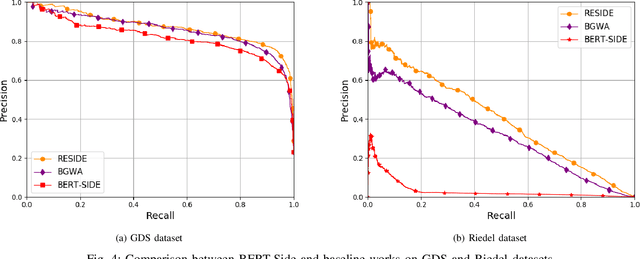
Relation extraction (RE) consists in categorizing the relationship between entities in a sentence. A recent paradigm to develop relation extractors is Distant Supervision (DS), which allows the automatic creation of new datasets by taking an alignment between a text corpus and a Knowledge Base (KB). KBs can sometimes also provide additional information to the RE task. One of the methods that adopt this strategy is the RESIDE model, which proposes a distantly-supervised neural relation extraction using side information from KBs. Considering that this method outperformed state-of-the-art baselines, in this paper, we propose a related approach to RESIDE also using additional side information, but simplifying the sentence encoding with BERT embeddings. Through experiments, we show the effectiveness of the proposed method in Google Distant Supervision and Riedel datasets concerning the BGWA and RESIDE baseline methods. Although Area Under the Curve is decreased because of unbalanced datasets, P@N results have shown that the use of BERT as sentence encoding allows superior performance to baseline methods.
Methodology and Results for the Competition on Semantic Similarity Evaluation and Entailment Recognition for PROPOR 2016
Sep 19, 2017In this paper, we present the methodology and the results obtained by our teams, dubbed Blue Man Group, in the ASSIN (from the Portuguese {\it Avalia\c{c}\~ao de Similaridade Sem\^antica e Infer\^encia Textual}) competition, held at PROPOR 2016\footnote{International Conference on the Computational Processing of the Portuguese Language - http://propor2016.di.fc.ul.pt/}. Our team's strategy consisted of evaluating methods based on semantic word vectors, following two distinct directions: 1) to make use of low-dimensional, compact, feature sets, and 2) deep learning-based strategies dealing with high-dimensional feature vectors. Evaluation results demonstrated that the first strategy was more promising, so that the results from the second strategy have been discarded. As a result, by considering the best run of each of the six teams, we have been able to achieve the best accuracy and F1 values in entailment recognition, in the Brazilian Portuguese set, and the best F1 score overall. In the semantic similarity task, our team was ranked second in the Brazilian Portuguese set, and third considering both sets.
Bus Travel Time Predictions Using Additive Models
Nov 28, 2014
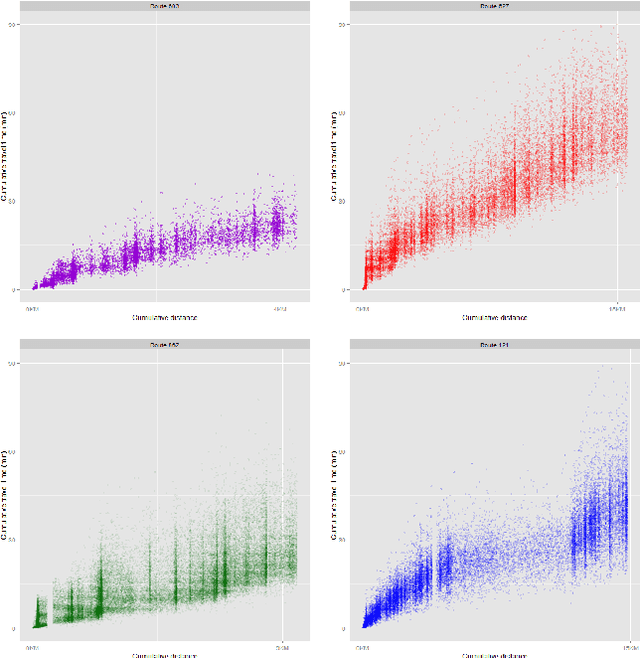
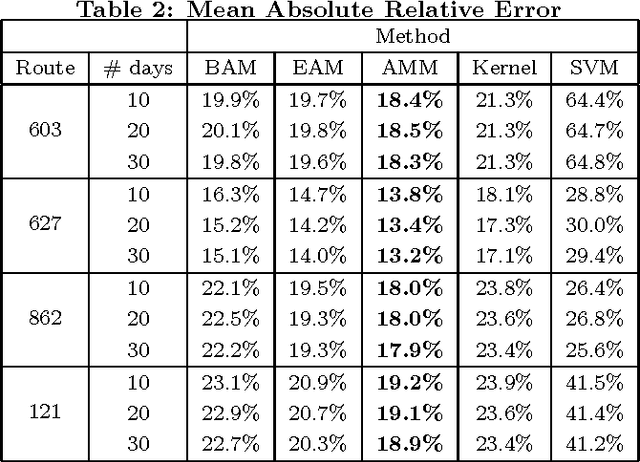
Many factors can affect the predictability of public bus services such as traffic, weather and local events. Other aspects, such as day of week or hour of day, may influence bus travel times as well, either directly or in conjunction with other variables. However, the exact nature of such relationships between travel times and predictor variables is, in most situations, not known. In this paper we develop a framework that allows for flexible modeling of bus travel times through the use of Additive Models. In particular, we model travel times as a sum of linear as well as nonlinear terms that are modeled as smooth functions of predictor variables. The proposed class of models provides a principled statistical framework that is highly flexible in terms of model building. The experimental results demonstrate uniformly superior performance of our best model as compared to previous prediction methods when applied to a very large GPS data set obtained from buses operating in the city of Rio de Janeiro.