 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Unsupervised Similarity-Based Aspect Extraction
Aug 25, 2020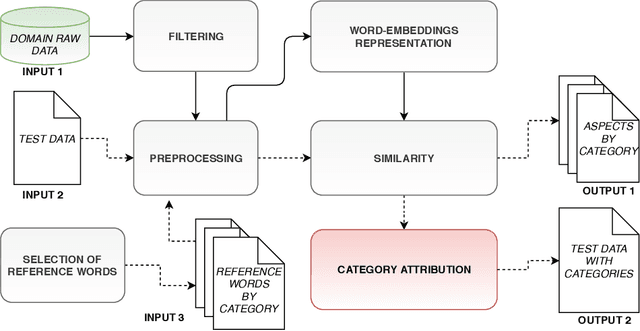
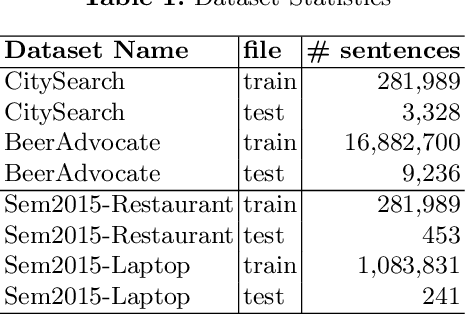
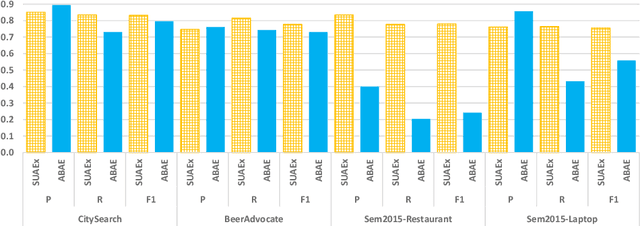
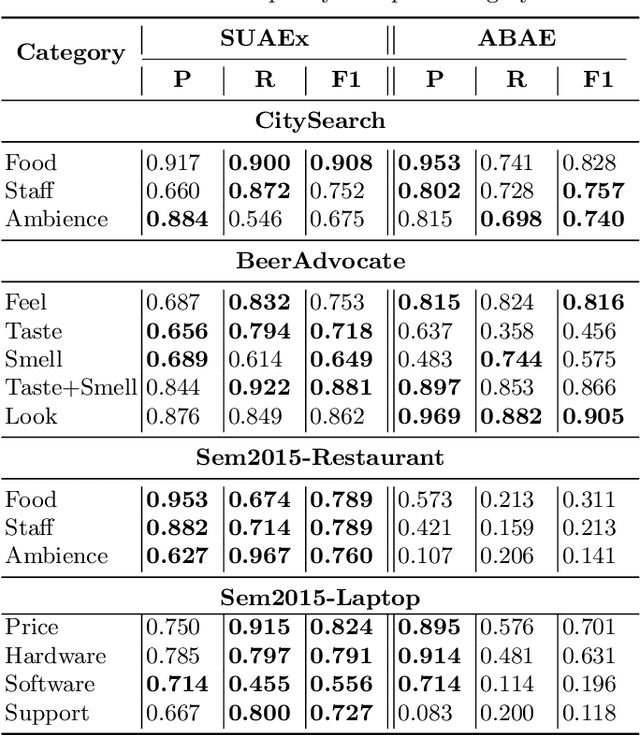
In the context of sentiment analysis, there has been growing interest in performing a finer granularity analysis focusing on the specific aspects of the entities being evaluated. This is the goal of Aspect-Based Sentiment Analysis (ABSA) which basically involves two tasks: aspect extraction and polarity detection. The first task is responsible for discovering the aspects mentioned in the review text and the second task assigns a sentiment orientation (positive, negative, or neutral) to that aspect. Currently, the state-of-the-art in ABSA consists of the application of deep learning methods such as recurrent, convolutional and attention neural networks. The limitation of these techniques is that they require a lot of training data and are computationally expensive. In this paper, we propose a simple approach called SUAEx for aspect extraction. SUAEx is unsupervised and relies solely on the similarity of word embeddings. Experimental results on datasets from three different domains have shown that SUAEx achieves results that can outperform the state-of-the-art attention-based approach at a fraction of the time.
BabelEnconding at SemEval-2020 Task 3: Contextual Similarity as a Combination of Multilingualism and Language Models
Aug 19, 2020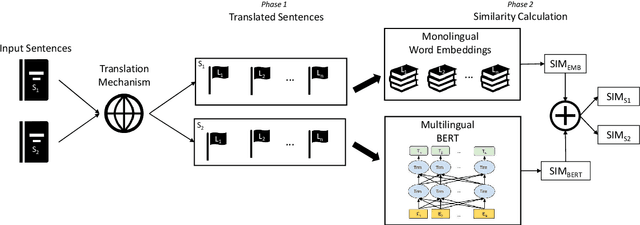
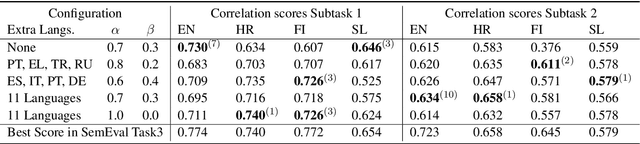
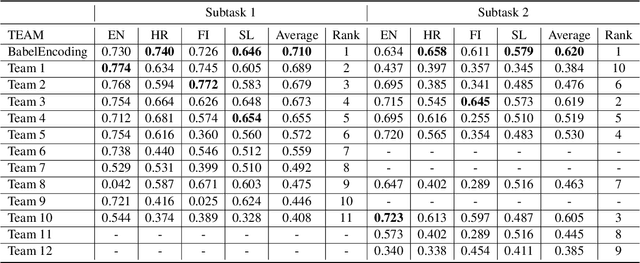

This paper describes the system submitted by our team (BabelEnconding) to SemEval-2020 Task 3: Predicting the Graded Effect of Context in Word Similarity. We propose an approach that relies on translation and multilingual language models in order to compute the contextual similarity between pairs of words. Our hypothesis is that evidence from additional languages can leverage the correlation with the human generated scores. BabelEnconding was applied to both subtasks and ranked among the top-3 in six out of eight task/language combinations and was the highest scoring system three times.