 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoBIn: A Transformer-Based Model For Risk Of Bias Inference With Machine Reading Comprehension
Oct 28, 2024Objective: Scientific publications play a crucial role in uncovering insights, testing novel drugs, and shaping healthcare policies. Accessing the quality of publications requires evaluating their Risk of Bias (RoB), a process typically conducted by human reviewers. In this study, we introduce a new dataset for machine reading comprehension and RoB assessment and present RoBIn (Risk of Bias Inference), an innovative model crafted to automate such evaluation. The model employs a dual-task approach, extracting evidence from a given context and assessing the RoB based on the gathered evidence. Methods: We use data from the Cochrane Database of Systematic Reviews (CDSR) as ground truth to label open-access clinical trial publications from PubMed. This process enabled us to develop training and test datasets specifically for machine reading comprehension and RoB inference. Additionally, we created extractive (RoBInExt) and generative (RoBInGen) Transformer-based approaches to extract relevant evidence and classify the RoB effectively. Results: RoBIn is evaluated across various settings and benchmarked against state-of-the-art methods for RoB inference, including large language models in multiple scenarios. In most cases, the best-performing RoBIn variant surpasses traditional machine learning and LLM-based approaches, achieving an ROC AUC of 0.83. Conclusion: Based on the evidence extracted from clinical trial reports, RoBIn performs a binary classification to decide whether the trial is at a low RoB or a high/unclear RoB. We found that both RoBInGen and RoBInExt are robust and have the best results in many settings.
Simple Unsupervised Similarity-Based Aspect Extraction
Aug 25, 2020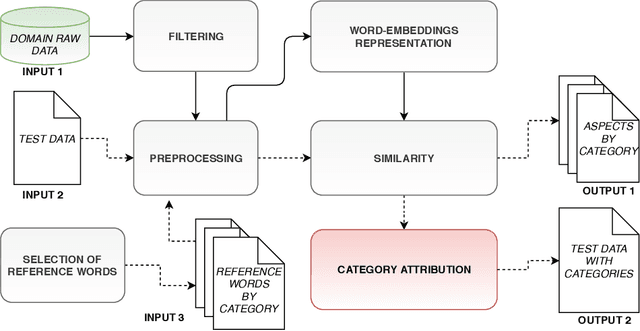
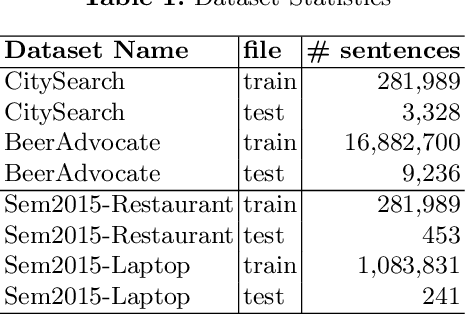
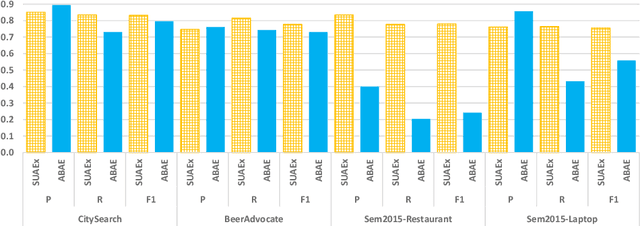
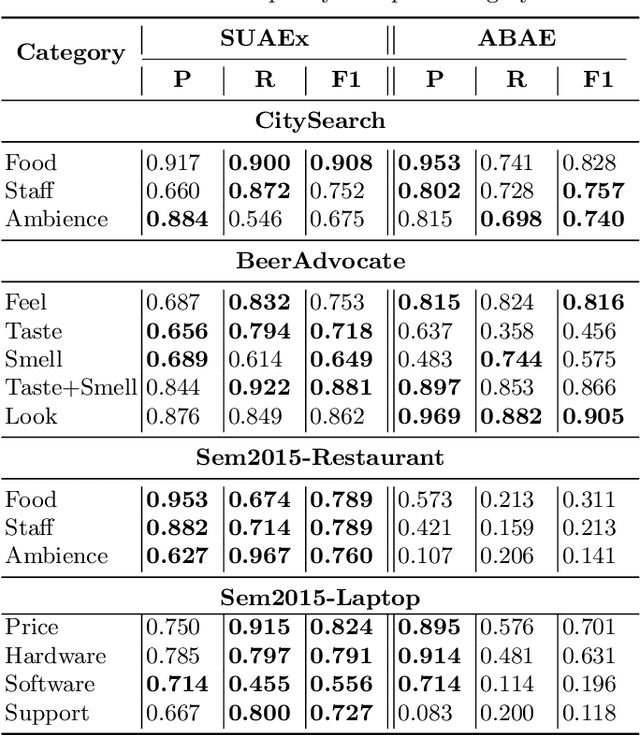
In the context of sentiment analysis, there has been growing interest in performing a finer granularity analysis focusing on the specific aspects of the entities being evaluated. This is the goal of Aspect-Based Sentiment Analysis (ABSA) which basically involves two tasks: aspect extraction and polarity detection. The first task is responsible for discovering the aspects mentioned in the review text and the second task assigns a sentiment orientation (positive, negative, or neutral) to that aspect. Currently, the state-of-the-art in ABSA consists of the application of deep learning methods such as recurrent, convolutional and attention neural networks. The limitation of these techniques is that they require a lot of training data and are computationally expensive. In this paper, we propose a simple approach called SUAEx for aspect extraction. SUAEx is unsupervised and relies solely on the similarity of word embeddings. Experimental results on datasets from three different domains have shown that SUAEx achieves results that can outperform the state-of-the-art attention-based approach at a fraction of the time.
Mono vs Multilingual Transformer-based Models: a Comparison across Several Language Tasks
Jul 19, 2020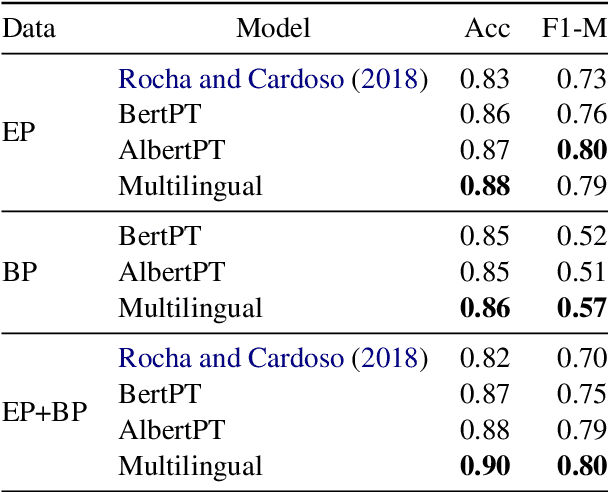
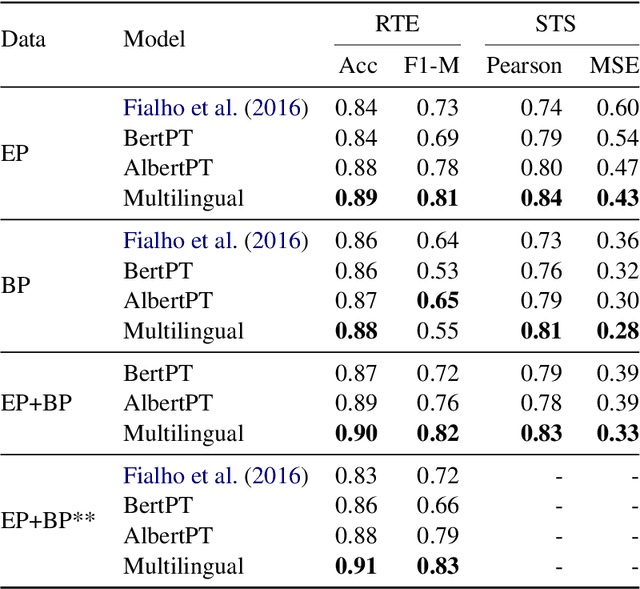
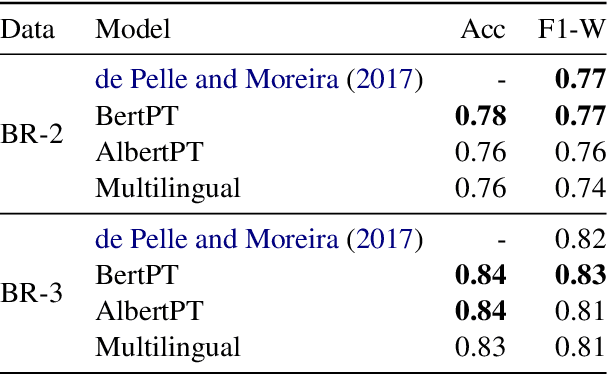
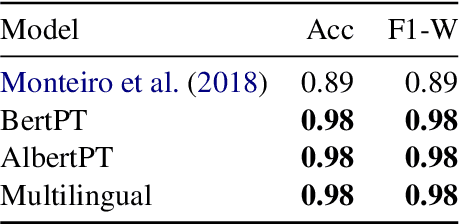
BERT (Bidirectional Encoder Representations from Transformers) and ALBERT (A Lite BERT) are methods for pre-training language models which can later be fine-tuned for a variety of Natural Language Understanding tasks. These methods have been applied to a number of such tasks (mostly in English), achieving results that outperform the state-of-the-art. In this paper, our contribution is twofold. First, we make available our trained BERT and Albert model for Portuguese. Second, we compare our monolingual and the standard multilingual models using experiments in semantic textual similarity, recognizing textual entailment, textual category classification, sentiment analysis, offensive comment detection, and fake news detection, to assess the effectiveness of the generated language representations. The results suggest that both monolingual and multilingual models are able to achieve state-of-the-art and the advantage of training a single language model, if any, is small.
A Large Parallel Corpus of Full-Text Scientific Articles
May 06, 2019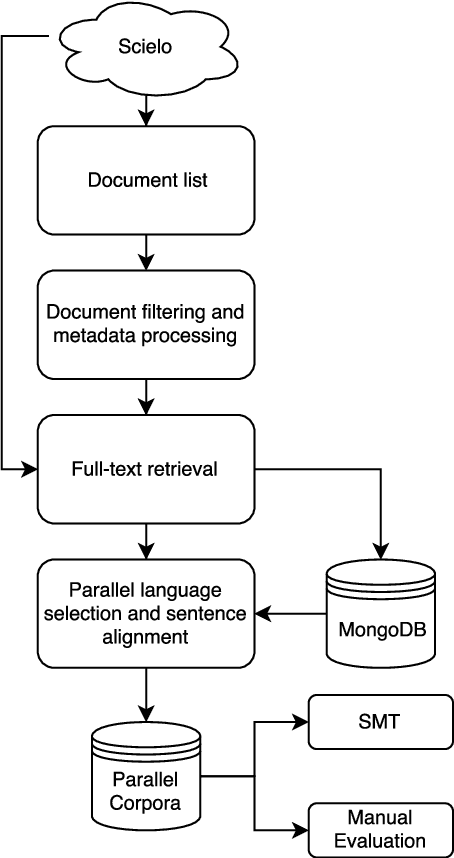
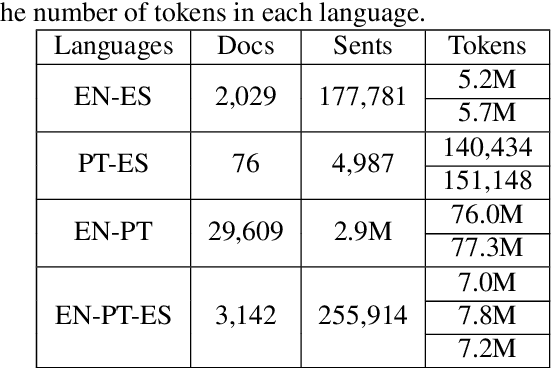
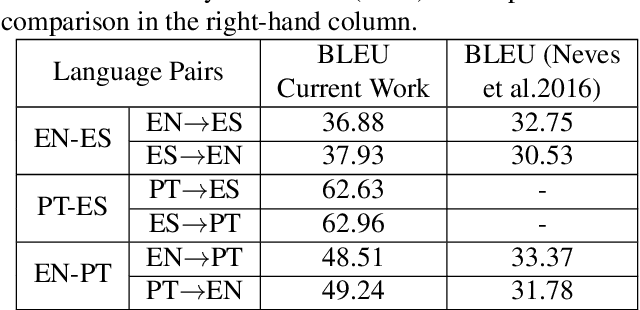
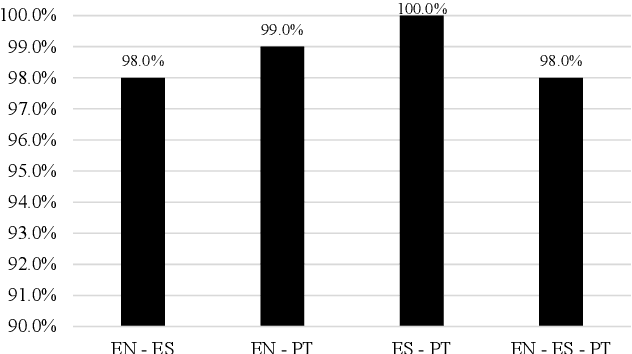
The Scielo database is an important source of scientific information in Latin America, containing articles from several research domains. A striking characteristic of Scielo is that many of its full-text contents are presented in more than one language, thus being a potential source of parallel corpora. In this article, we present the development of a parallel corpus from Scielo in three languages: English, Portuguese, and Spanish. Sentences were automatically aligned using the Hunalign algorithm for all language pairs, and for a subset of trilingual articles also. We demonstrate the capabilities of our corpus by training a Statistical Machine Translation system (Moses) for each language pair, which outperformed related works on scientific articles. Sentence alignment was also manually evaluated, presenting an average of 98.8% correctly aligned sentences across all languages. Our parallel corpus is freely available in the TMX format, with complementary information regarding article metadata.