 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Schema References in Keyword Queries over Relational Databases
Mar 11, 2022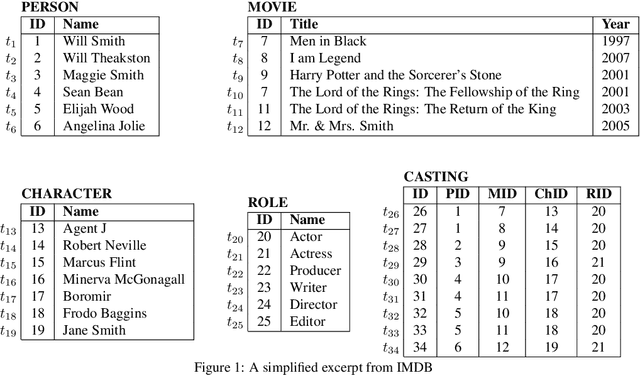


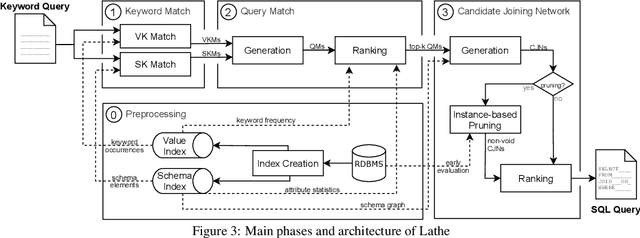
Relational Keyword Search (R-KwS) systems enable naive/informal users to explore and retrieve information from relational databases without knowing schema details or query languages. These systems take the keywords from the input query, locate the elements of the target database that correspond to these keywords, and look for ways to "connect" these elements using information on referential integrity constraints, i.e., key/foreign key pairs. Although several such systems have been proposed in the literature, most of them only support queries whose keywords refer to the contents of the target database and just very few support queries in which keywords refer to elements of the database schema. This paper proposes LATHE, a novel R-KwS designed to support such queries. To this end, in our work, we first generalize the well-known concepts of Query Matches (QMs) and Candidate Joining Networks (CJNs) to handle keywords referring to schema elements and propose new algorithms to generate them. Then, we introduce an approach to automatically select the CJNs that are more likely to represent the user intent when issuing a keyword query. This approach includes two major innovations: a ranking algorithm for selecting better QMs, yielding the generation of fewer but better CJNs, and an eager evaluation strategy for pruning void useless CJNs. We present a comprehensive set of experiments performed with query sets and datasets previously used in experiments with state-of-the-art R-KwS systems and methods. Our results indicate that LATHE can handle a wider variety of keyword queries while remaining highly effective, even for large databases with intricate schemas.
BabelEnconding at SemEval-2020 Task 3: Contextual Similarity as a Combination of Multilingualism and Language Models
Aug 19, 2020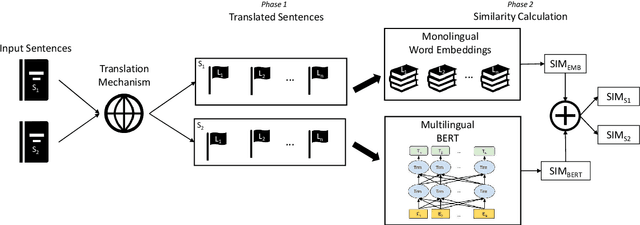
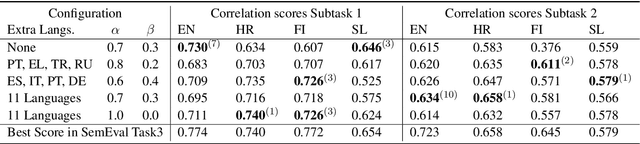
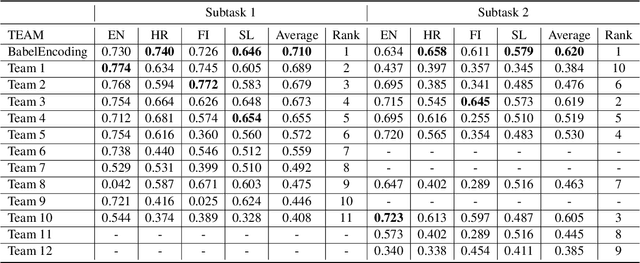

This paper describes the system submitted by our team (BabelEnconding) to SemEval-2020 Task 3: Predicting the Graded Effect of Context in Word Similarity. We propose an approach that relies on translation and multilingual language models in order to compute the contextual similarity between pairs of words. Our hypothesis is that evidence from additional languages can leverage the correlation with the human generated scores. BabelEnconding was applied to both subtasks and ranked among the top-3 in six out of eight task/language combinations and was the highest scoring system three times.