 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Programming Skills with Source Code Embeddings for Context-aware Exercise Recommendation
Feb 10, 2026In this paper, we propose a context-aware recommender system that models students' programming skills using embeddings of the source code they submit throughout a course. These embeddings predict students' skills across multiple programming topics, producing profiles that are matched to the skills required by unseen homework problems. To generate recommendations, we compute the cosine similarity between student profiles and problem skill vectors, ranking exercises according to their alignment with each student's current abilities. We evaluated our approach using real data from students and exercises in an introductory programming course at our university. First, we assessed the effectiveness of our source code embeddings for predicting skills, comparing them with token-based and graph-based alternatives. Results showed that Jina embeddings outperformed TF-IDF, CodeBERT-cpp, and GraphCodeBERT across most skills. Additionally, we evaluated the system's ability to recommend exercises aligned with weekly course content by analyzing student submissions collected over seven course offerings. Our approach consistently produced more suitable recommendations than baselines based on correctness or solution time, indicating that predicted programming skills provide a stronger signal for problem recommendation.
Long-Form Text-to-Music Generation with Adaptive Prompts: A Case of Study in Tabletop Role-Playing Games Soundtracks
Nov 06, 2024
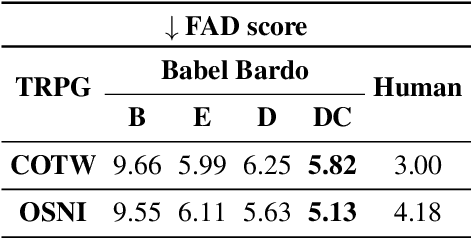


This paper investigates the capabilities of text-to-audio music generation models in producing long-form music with prompts that change over time, focusing on soundtrack generation for Tabletop Role-Playing Games (TRPGs). We introduce Babel Bardo, a system that uses Large Language Models (LLMs) to transform speech transcriptions into music descriptions for controlling a text-to-music model. Four versions of Babel Bardo were compared in two TRPG campaigns: a baseline using direct speech transcriptions, and three LLM-based versions with varying approaches to music description generation. Evaluations considered audio quality, story alignment, and transition smoothness. Results indicate that detailed music descriptions improve audio quality while maintaining consistency across consecutive descriptions enhances story alignment and transition smoothness.
The NES Video-Music Database: A Dataset of Symbolic Video Game Music Paired with Gameplay Videos
Apr 05, 2024Neural models are one of the most popular approaches for music generation, yet there aren't standard large datasets tailored for learning music directly from game data. To address this research gap, we introduce a novel dataset named NES-VMDB, containing 98,940 gameplay videos from 389 NES games, each paired with its original soundtrack in symbolic format (MIDI). NES-VMDB is built upon the Nintendo Entertainment System Music Database (NES-MDB), encompassing 5,278 music pieces from 397 NES games. Our approach involves collecting long-play videos for 389 games of the original dataset, slicing them into 15-second-long clips, and extracting the audio from each clip. Subsequently, we apply an audio fingerprinting algorithm (similar to Shazam) to automatically identify the corresponding piece in the NES-MDB dataset. Additionally, we introduce a baseline method based on the Controllable Music Transformer to generate NES music conditioned on gameplay clips. We evaluated this approach with objective metrics, and the results showed that the conditional CMT improves musical structural quality when compared to its unconditional counterpart. Moreover, we used a neural classifier to predict the game genre of the generated pieces. Results showed that the CMT generator can learn correlations between gameplay videos and game genres, but further research has to be conducted to achieve human-level performance.
Choosing Well Your Opponents: How to Guide the Synthesis of Programmatic Strategies
Jul 24, 2023This paper introduces Local Learner (2L), an algorithm for providing a set of reference strategies to guide the search for programmatic strategies in two-player zero-sum games. Previous learning algorithms, such as Iterated Best Response (IBR), Fictitious Play (FP), and Double-Oracle (DO), can be computationally expensive or miss important information for guiding search algorithms. 2L actively selects a set of reference strategies to improve the search signal. We empirically demonstrate the advantages of our approach while guiding a local search algorithm for synthesizing strategies in three games, including MicroRTS, a challenging real-time strategy game. Results show that 2L learns reference strategies that provide a stronger search signal than IBR, FP, and DO. We also simulate a tournament of MicroRTS, where a synthesizer using 2L outperformed the winners of the two latest MicroRTS competitions, which were programmatic strategies written by human programmers.
Controlling Perceived Emotion in Symbolic Music Generation with Monte Carlo Tree Search
Sep 01, 2022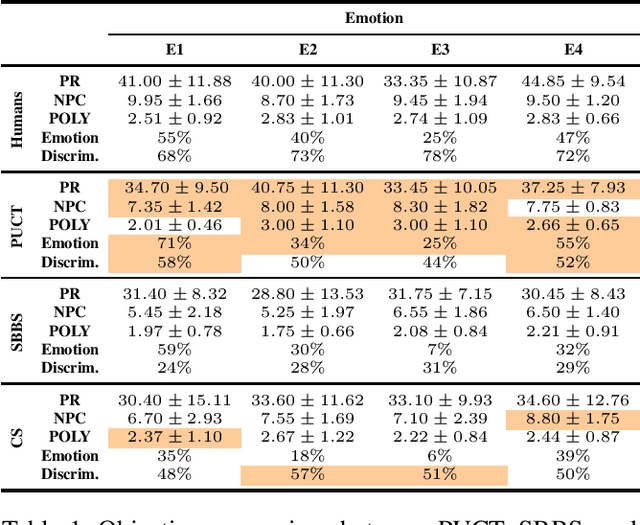


This paper presents a new approach for controlling emotion in symbolic music generation with Monte Carlo Tree Search. We use Monte Carlo Tree Search as a decoding mechanism to steer the probability distribution learned by a language model towards a given emotion. At every step of the decoding process, we use Predictor Upper Confidence for Trees (PUCT) to search for sequences that maximize the average values of emotion and quality as given by an emotion classifier and a discriminator, respectively. We use a language model as PUCT's policy and a combination of the emotion classifier and the discriminator as its value function. To decode the next token in a piece of music, we sample from the distribution of node visits created during the search. We evaluate the quality of the generated samples with respect to human-composed pieces using a set of objective metrics computed directly from the generated samples. We also perform a user study to evaluate how human subjects perceive the generated samples' quality and emotion. We compare PUCT against Stochastic Bi-Objective Beam Search (SBBS) and Conditional Sampling (CS). Results suggest that PUCT outperforms SBBS and CS in almost all metrics of music quality and emotion.
Learning to Generate Music With Sentiment
Mar 09, 2021
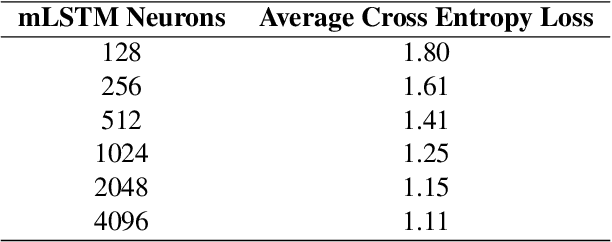
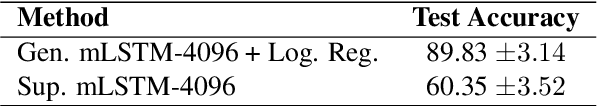
Deep Learning models have shown very promising results in automatically composing polyphonic music pieces. However, it is very hard to control such models in order to guide the compositions towards a desired goal. We are interested in controlling a model to automatically generate music with a given sentiment. This paper presents a generative Deep Learning model that can be directed to compose music with a given sentiment. Besides music generation, the same model can be used for sentiment analysis of symbolic music. We evaluate the accuracy of the model in classifying sentiment of symbolic music using a new dataset of video game soundtracks. Results show that our model is able to obtain good prediction accuracy. A user study shows that human subjects agreed that the generated music has the intended sentiment, however negative pieces can be ambiguous.
Computer-Generated Music for Tabletop Role-Playing Games
Aug 16, 2020In this paper we present Bardo Composer, a system to generate background music for tabletop role-playing games. Bardo Composer uses a speech recognition system to translate player speech into text, which is classified according to a model of emotion. Bardo Composer then uses Stochastic Bi-Objective Beam Search, a variant of Stochastic Beam Search that we introduce in this paper, with a neural model to generate musical pieces conveying the desired emotion. We performed a user study with 116 participants to evaluate whether people are able to correctly identify the emotion conveyed in the pieces generated by the system. In our study we used pieces generated for Call of the Wild, a Dungeons and Dragons campaign available on YouTube. Our results show that human subjects could correctly identify the emotion of the generated music pieces as accurately as they were able to identify the emotion of pieces written by humans.