 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule Synergy Analysis using LLMs: State of the Art and Implications
Aug 27, 2025



Large language models (LLMs) have demonstrated strong performance across a variety of domains, including logical reasoning, mathematics, and more. In this paper, we investigate how well LLMs understand and reason about complex rule interactions in dynamic environments, such as card games. We introduce a dataset of card synergies from the game Slay the Spire, where pairs of cards are classified based on their positive, negative, or neutral interactions. Our evaluation shows that while LLMs excel at identifying non-synergistic pairs, they struggle with detecting positive and, particularly, negative synergies. We categorize common error types, including issues with timing, defining game states, and following game rules. Our findings suggest directions for future research to improve model performance in predicting the effect of rules and their interactions.
Procedural Generation of Complex Roundabouts for Autonomous Vehicle Testing
Mar 31, 2023High-definition roads are an essential component of realistic driving scenario simulation for autonomous vehicle testing. Roundabouts are one of the key road segments that have not been thoroughly investigated. Based on the geometric constraints of the nearby road structure, this work presents a novel method for procedurally building roundabouts. The suggested method can result in roundabout lanes that are not perfectly circular and resemble real-world roundabouts by allowing approaching roadways to be connected to a roundabout at any angle. One can easily incorporate the roundabout in their HD road generation process or use the standalone roundabouts in scenario-based testing of autonomous driving.
Controlling Perceived Emotion in Symbolic Music Generation with Monte Carlo Tree Search
Sep 01, 2022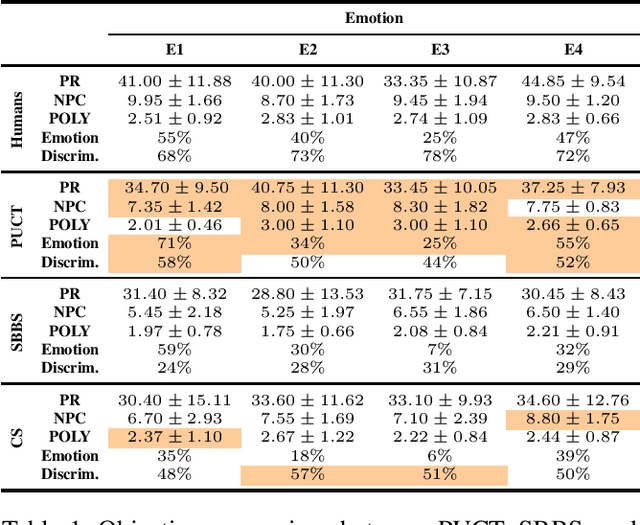


This paper presents a new approach for controlling emotion in symbolic music generation with Monte Carlo Tree Search. We use Monte Carlo Tree Search as a decoding mechanism to steer the probability distribution learned by a language model towards a given emotion. At every step of the decoding process, we use Predictor Upper Confidence for Trees (PUCT) to search for sequences that maximize the average values of emotion and quality as given by an emotion classifier and a discriminator, respectively. We use a language model as PUCT's policy and a combination of the emotion classifier and the discriminator as its value function. To decode the next token in a piece of music, we sample from the distribution of node visits created during the search. We evaluate the quality of the generated samples with respect to human-composed pieces using a set of objective metrics computed directly from the generated samples. We also perform a user study to evaluate how human subjects perceive the generated samples' quality and emotion. We compare PUCT against Stochastic Bi-Objective Beam Search (SBBS) and Conditional Sampling (CS). Results suggest that PUCT outperforms SBBS and CS in almost all metrics of music quality and emotion.
Learning to Generate Music With Sentiment
Mar 09, 2021
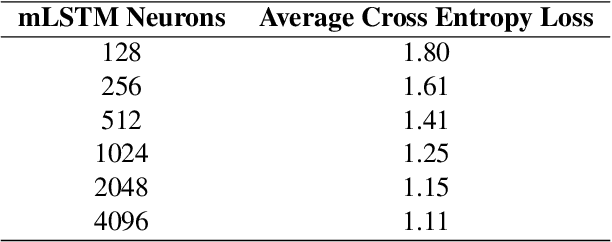
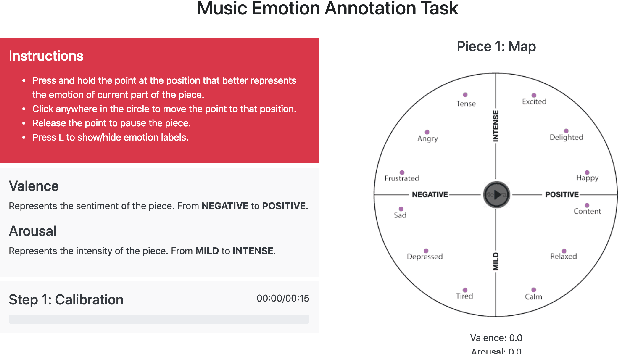
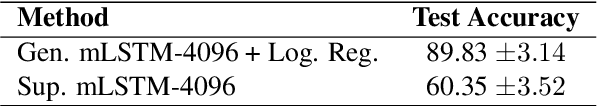
Deep Learning models have shown very promising results in automatically composing polyphonic music pieces. However, it is very hard to control such models in order to guide the compositions towards a desired goal. We are interested in controlling a model to automatically generate music with a given sentiment. This paper presents a generative Deep Learning model that can be directed to compose music with a given sentiment. Besides music generation, the same model can be used for sentiment analysis of symbolic music. We evaluate the accuracy of the model in classifying sentiment of symbolic music using a new dataset of video game soundtracks. Results show that our model is able to obtain good prediction accuracy. A user study shows that human subjects agreed that the generated music has the intended sentiment, however negative pieces can be ambiguous.
Computer-Generated Music for Tabletop Role-Playing Games
Aug 16, 2020In this paper we present Bardo Composer, a system to generate background music for tabletop role-playing games. Bardo Composer uses a speech recognition system to translate player speech into text, which is classified according to a model of emotion. Bardo Composer then uses Stochastic Bi-Objective Beam Search, a variant of Stochastic Beam Search that we introduce in this paper, with a neural model to generate musical pieces conveying the desired emotion. We performed a user study with 116 participants to evaluate whether people are able to correctly identify the emotion conveyed in the pieces generated by the system. In our study we used pieces generated for Call of the Wild, a Dungeons and Dragons campaign available on YouTube. Our results show that human subjects could correctly identify the emotion of the generated music pieces as accurately as they were able to identify the emotion of pieces written by humans.