 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling missing data in model-based clustering
Jun 04, 2020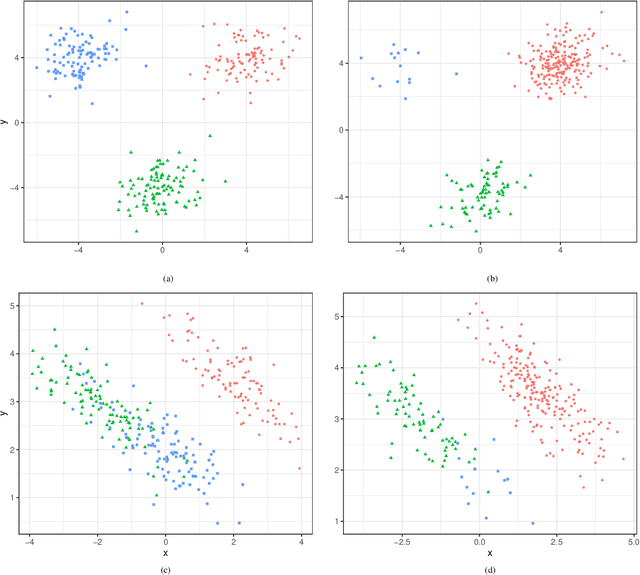
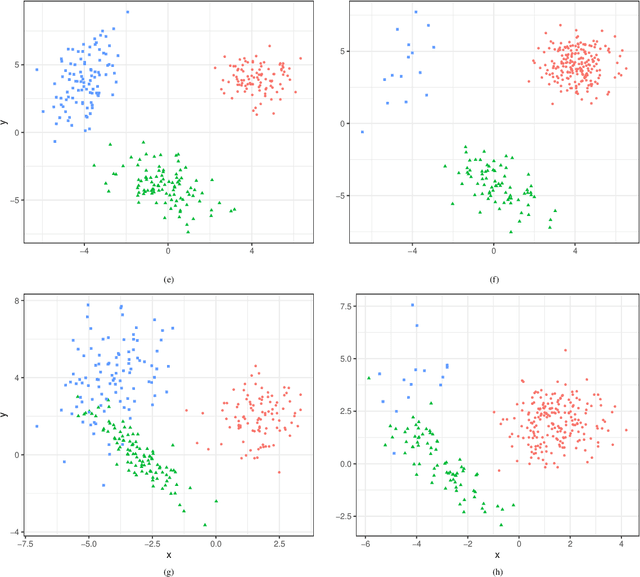
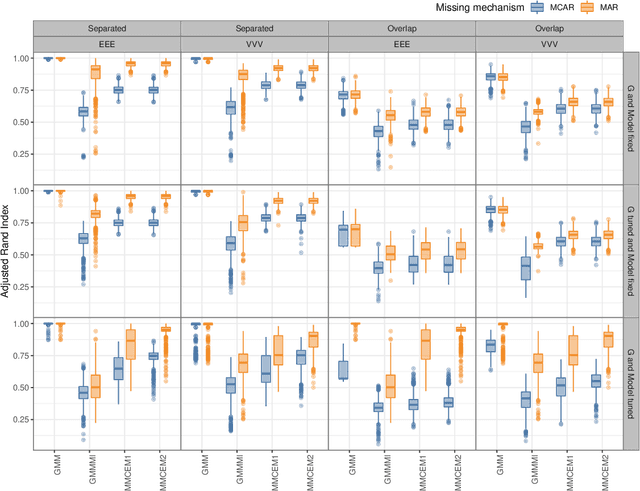

Gaussian Mixture models (GMMs) are a powerful tool for clustering, classification and density estimation when clustering structures are embedded in the data. The presence of missing values can largely impact the GMMs estimation process, thus handling missing data turns out to be a crucial point in clustering, classification and density estimation. Several techniques have been developed to impute the missing values before model estimation. Among these, multiple imputation is a simple and useful general approach to handle missing data. In this paper we propose two different methods to fit Gaussian mixtures in the presence of missing data. Both methods use a variant of the Monte Carlo Expectation-Maximisation (MCEM) algorithm for data augmentation. Thus, multiple imputations are performed during the E-step, followed by the standard M-step for a given eigen-decomposed component-covariance matrix. We show that the proposed methods outperform the multiple imputation approach, both in terms of clusters identification and density estimation.
A fast and efficient Modal EM algorithm for Gaussian mixtures
Feb 10, 2020



In the modal approach to clustering, clusters are defined as the local maxima of the underlying probability density function, where the latter can be estimated either non-parametrically or using finite mixture models. Thus, clusters are closely related to certain regions around the density modes, and every cluster corresponds to a bump of the density. The Modal EM algorithm is an iterative procedure that can identify the local maxima of any density function. In this contribution, we propose a fast and efficient Modal EM algorithm to be used when the density function is estimated through a finite mixture of Gaussian distributions with parsimonious component-covariance structures. After describing the procedure, we apply the proposed Modal EM algorithm on both simulated and real data examples, showing its high flexibility in several contexts.
Projection pursuit based on Gaussian mixtures and evolutionary algorithms
Dec 27, 2019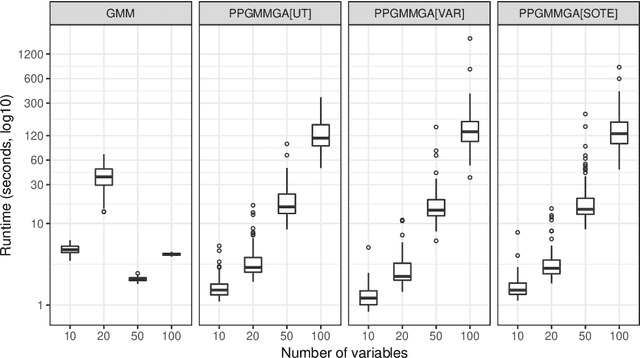



We propose a projection pursuit (PP) algorithm based on Gaussian mixture models (GMMs). The negentropy obtained from a multivariate density estimated by GMMs is adopted as the PP index to be maximised. For a fixed dimension of the projection subspace, the GMM-based density estimation is projected onto that subspace, where an approximation of the negentropy for Gaussian mixtures is computed. Then, Genetic Algorithms (GAs) are used to find the optimal, orthogonal projection basis by maximising the former approximation. We show that this semi-parametric approach to PP is flexible and allows highly informative structures to be detected, by projecting multivariate datasets onto a subspace, where the data can be feasibly visualised. The performance of the proposed approach is shown on both artificial and real datasets.
Model-based SIR for dimension reduction
Aug 10, 2015



A new dimension reduction method based on Gaussian finite mixtures is proposed as an extension to sliced inverse regression (SIR). The model-based SIR (MSIR) approach allows the main limitation of SIR to be overcome, i.e., failure in the presence of regression symmetric relationships, without the need to impose further assumptions. Extensive numerical studies are presented to compare the new method with some of most popular dimension reduction methods, such as SIR, sliced average variance estimation, principal Hessian direction, and directional regression. MSIR appears sufficiently flexible to accommodate various regression functions, and its performance is comparable with or better, particularly as sample size grows, than other available methods. Lastly, MSIR is illustrated with two real data examples about ozone concentration regression, and hand-written digit classification.
Dimension reduction for model-based clustering
Aug 07, 2015
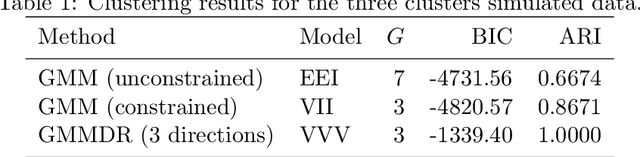

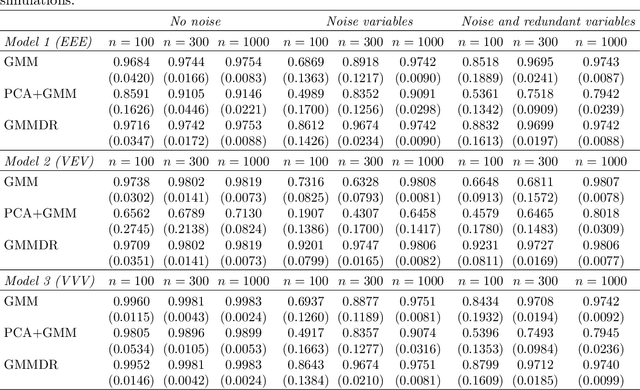
We introduce a dimension reduction method for visualizing the clustering structure obtained from a finite mixture of Gaussian densities. Information on the dimension reduction subspace is obtained from the variation on group means and, depending on the estimated mixture model, on the variation on group covariances. The proposed method aims at reducing the dimensionality by identifying a set of linear combinations, ordered by importance as quantified by the associated eigenvalues, of the original features which capture most of the cluster structure contained in the data. Observations may then be projected onto such a reduced subspace, thus providing summary plots which help to visualize the clustering structure. These plots can be particularly appealing in the case of high-dimensional data and noisy structure. The new constructed variables capture most of the clustering information available in the data, and they can be further reduced to improve clustering performance. We illustrate the approach on both simulated and real data sets.