 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Insect-inspired Approach for Visual Point-goal Navigation
Jan 23, 2026In this work we develop a novel insect-inspired agent for visual point-goal navigation. This combines abstracted models of two insect brain structures that have been implicated, respectively, in associative learning and path integration. We draw an analogy between the formal benchmark of the Habitat point-goal navigation task and the ability of insects to learn and refine visually guided paths around obstacles between a discovered food location and their nest. We demonstrate that the simple insect-inspired agent exhibits performance comparable to recent SOTA models at many orders of magnitude less computational cost. Testing in a more realistic simulated environment shows the approach is robust to perturbations.
Vision-based route following by an embodied insect-inspired sparse neural network
Mar 31, 2023We compared the efficiency of the FlyHash model, an insect-inspired sparse neural network (Dasgupta et al., 2017), to similar but non-sparse models in an embodied navigation task. This requires a model to control steering by comparing current visual inputs to memories stored along a training route. We concluded the FlyHash model is more efficient than others, especially in terms of data encoding.
Program synthesis performance constrained by non-linear spatial relations in Synthetic Visual Reasoning Test
Nov 19, 2019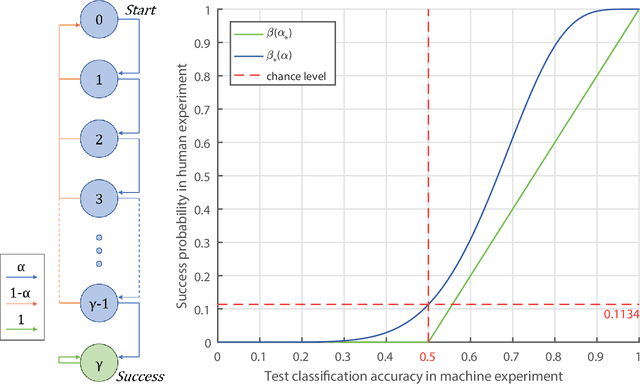

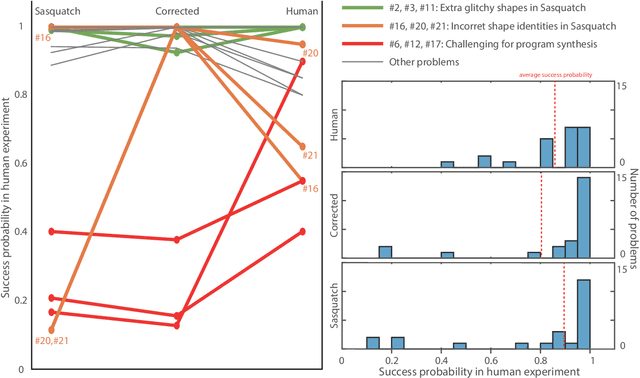

Despite remarkable advances in automated visual recognition by machines, some visual tasks remain challenging for machines. Fleuret et al. (2011) introduced the Synthetic Visual Reasoning Test (SVRT) to highlight this point, which required classification of images consisting of randomly generated shapes based on hidden abstract rules using only a few examples. Ellis et al. (2015) demonstrated that a program synthesis approach could solve some of the SVRT problems with unsupervised, few-shot learning, whereas they remained challenging for several convolutional neural networks trained with thousands of examples. Here we re-considered the human and machine experiments, because they followed different protocols and yielded different statistics. We thus proposed a quantitative reintepretation of the data between the protocols, so that we could make fair comparison between human and machine performance. We improved the program synthesis classifier by correcting the image parsings, and compared the results to the performance of other machine agents and human subjects. We grouped the SVRT problems into different types by the two aspects of the core characteristics for classification: shape specification and location relation. We found that the program synthesis classifier could not solve problems involving shape distances, because it relied on symbolic computation which scales poorly with input dimension and adding distances into such computation would increase the dimension combinatorially with the number of shapes in an image. Therefore, although the program synthesis classifier is capable of abstract reasoning, its performance is highly constrained by the accessible information in image parsings.