 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Clustering of Ecological Momentary Assessment Data Through Temporal and Feature Attention
May 08, 2024In the field of psychopathology, Ecological Momentary Assessment (EMA) studies offer rich individual data on psychopathology-relevant variables (e.g., affect, behavior, etc) in real-time. EMA data is collected dynamically, represented as complex multivariate time series (MTS). Such information is crucial for a better understanding of mental disorders at the individual- and group-level. More specifically, clustering individuals in EMA data facilitates uncovering and studying the commonalities as well as variations of groups in the population. Nevertheless, since clustering is an unsupervised task and true EMA grouping is not commonly available, the evaluation of clustering is quite challenging. An important aspect of evaluation is clustering explainability. Thus, this paper proposes an attention-based interpretable framework to identify the important time-points and variables that play primary roles in distinguishing between clusters. A key part of this study is to examine ways to analyze, summarize, and interpret the attention weights as well as evaluate the patterns underlying the important segments of the data that differentiate across clusters. To evaluate the proposed approach, an EMA dataset of 187 individuals grouped in 3 clusters is used for analyzing the derived attention-based importance attributes. More specifically, this analysis provides the distinct characteristics at the cluster-, feature- and individual level. Such clustering explanations could be beneficial for generalizing existing concepts of mental disorders, discovering new insights, and even enhancing our knowledge at an individual level.
Exploiting Individual Graph Structures to Enhance Ecological Momentary Assessment (EMA) Forecasting
Mar 28, 2024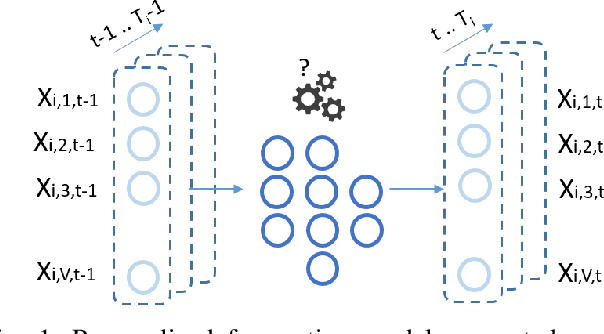
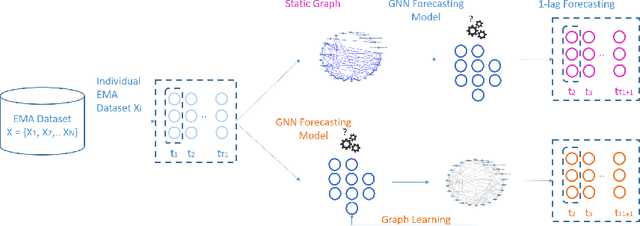
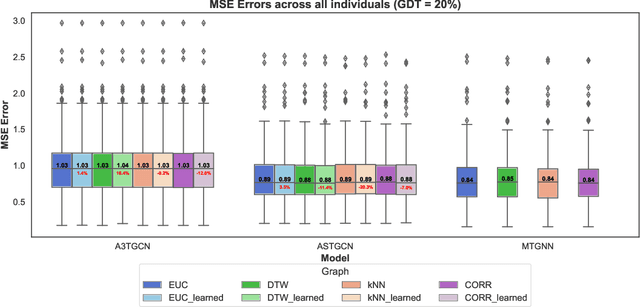
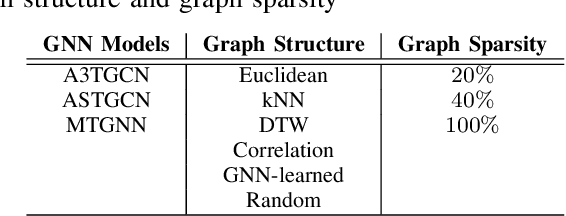
In the evolving field of psychopathology, the accurate assessment and forecasting of data derived from Ecological Momentary Assessment (EMA) is crucial. EMA offers contextually-rich psychopathological measurements over time, that practically lead to Multivariate Time Series (MTS) data. Thus, many challenges arise in analysis from the temporal complexities inherent in emotional, behavioral, and contextual EMA data as well as their inter-dependencies. To address both of these aspects, this research investigates the performance of Recurrent and Temporal Graph Neural Networks (GNNs). Overall, GNNs, by incorporating additional information from graphs reflecting the inner relationships between the variables, notably enhance the results by decreasing the Mean Squared Error (MSE) to 0.84 compared to the baseline LSTM model at 1.02. Therefore, the effect of constructing graphs with different characteristics on GNN performance is also explored. Additionally, GNN-learned graphs, which are dynamically refined during the training process, were evaluated. Using such graphs showed a similarly good performance. Thus, graph learning proved also promising for other GNN methods, potentially refining the pre-defined graphs.
Model-based Clustering of Individuals' Ecological Momentary Assessment Time-series Data for Improving Forecasting Performance
Oct 11, 2023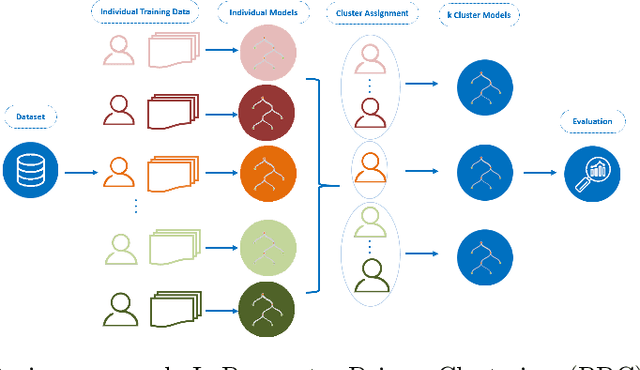


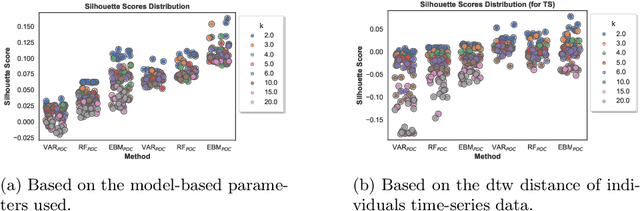
Through Ecological Momentary Assessment (EMA) studies, a number of time-series data is collected across multiple individuals, continuously monitoring various items of emotional behavior. Such complex data is commonly analyzed in an individual level, using personalized models. However, it is believed that additional information of similar individuals is likely to enhance these models leading to better individuals' description. Thus, clustering is investigated with an aim to group together the most similar individuals, and subsequently use this information in group-based models in order to improve individuals' predictive performance. More specifically, two model-based clustering approaches are examined, where the first is using model-extracted parameters of personalized models, whereas the second is optimized on the model-based forecasting performance. Both methods are then analyzed using intrinsic clustering evaluation measures (e.g. Silhouette coefficients) as well as the performance of a downstream forecasting scheme, where each forecasting group-model is devoted to describe all individuals belonging to one cluster. Among these, clustering based on performance shows the best results, in terms of all examined evaluation measures. As another level of evaluation, those group-models' performance is compared to three baseline scenarios, the personalized, the all-in-one group and the random group-based concept. According to this comparison, the superiority of clustering-based methods is again confirmed, indicating that the utilization of group-based information could be effectively enhance the overall performance of all individuals' data.
Clustering individuals based on multivariate EMA time-series data
Dec 02, 2022In the field of psychopathology, Ecological Momentary Assessment (EMA) methodological advancements have offered new opportunities to collect time-intensive, repeated and intra-individual measurements. This way, a large amount of data has become available, providing the means for further exploring mental disorders. Consequently, advanced machine learning (ML) methods are needed to understand data characteristics and uncover hidden and meaningful relationships regarding the underlying complex psychological processes. Among other uses, ML facilitates the identification of similar patterns in data of different individuals through clustering. This paper focuses on clustering multivariate time-series (MTS) data of individuals into several groups. Since clustering is an unsupervised problem, it is challenging to assess whether the resulting grouping is successful. Thus, we investigate different clustering methods based on different distance measures and assess them for the stability and quality of the derived clusters. These clustering steps are illustrated on a real-world EMA dataset, including 33 individuals and 15 variables. Through evaluation, the results of kernel-based clustering methods appear promising to identify meaningful groups in the data. So, efficient representations of EMA data play an important role in clustering.
Using Explainable Boosting Machine to Compare Idiographic and Nomothetic Approaches for Ecological Momentary Assessment Data
Apr 04, 2022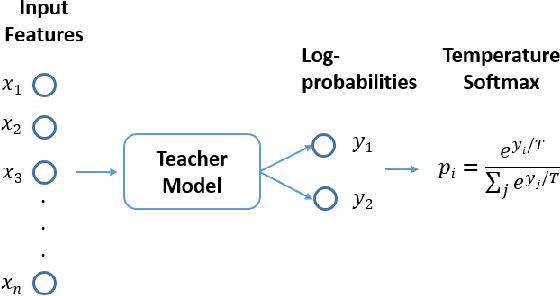

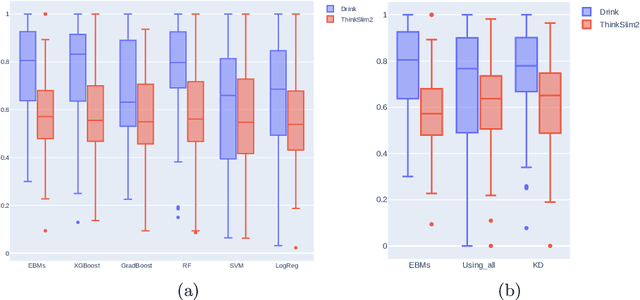
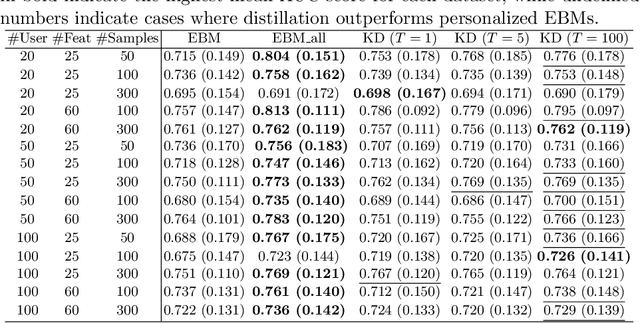
Previous research on EMA data of mental disorders was mainly focused on multivariate regression-based approaches modeling each individual separately. This paper goes a step further towards exploring the use of non-linear interpretable machine learning (ML) models in classification problems. ML models can enhance the ability to accurately predict the occurrence of different behaviors by recognizing complicated patterns between variables in data. To evaluate this, the performance of various ensembles of trees are compared to linear models using imbalanced synthetic and real-world datasets. After examining the distributions of AUC scores in all cases, non-linear models appear to be superior to baseline linear models. Moreover, apart from personalized approaches, group-level prediction models are also likely to offer an enhanced performance. According to this, two different nomothetic approaches to integrate data of more than one individuals are examined, one using directly all data during training and one based on knowledge distillation. Interestingly, it is observed that in one of the two real-world datasets, knowledge distillation method achieves improved AUC scores (mean relative change of +17\% compared to personalized) showing how it can benefit EMA data classification and performance.