 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Clustering of Individuals' Ecological Momentary Assessment Time-series Data for Improving Forecasting Performance
Paper and Code
Oct 11, 2023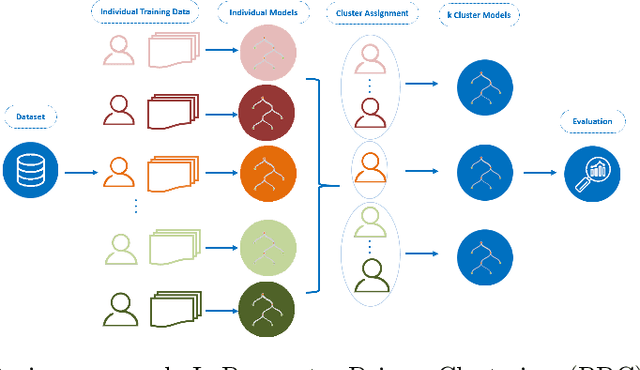


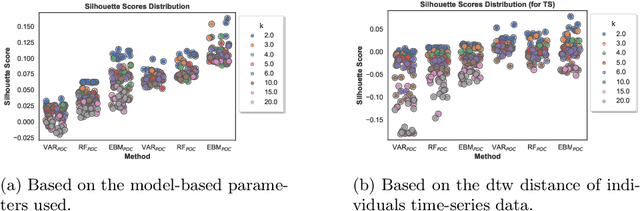
Through Ecological Momentary Assessment (EMA) studies, a number of time-series data is collected across multiple individuals, continuously monitoring various items of emotional behavior. Such complex data is commonly analyzed in an individual level, using personalized models. However, it is believed that additional information of similar individuals is likely to enhance these models leading to better individuals' description. Thus, clustering is investigated with an aim to group together the most similar individuals, and subsequently use this information in group-based models in order to improve individuals' predictive performance. More specifically, two model-based clustering approaches are examined, where the first is using model-extracted parameters of personalized models, whereas the second is optimized on the model-based forecasting performance. Both methods are then analyzed using intrinsic clustering evaluation measures (e.g. Silhouette coefficients) as well as the performance of a downstream forecasting scheme, where each forecasting group-model is devoted to describe all individuals belonging to one cluster. Among these, clustering based on performance shows the best results, in terms of all examined evaluation measures. As another level of evaluation, those group-models' performance is compared to three baseline scenarios, the personalized, the all-in-one group and the random group-based concept. According to this comparison, the superiority of clustering-based methods is again confirmed, indicating that the utilization of group-based information could be effectively enhance the overall performance of all individuals' data.