 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Neural Language Models' Insensitivity to Word-Order
Jul 29, 2021



Recent research analyzing the sensitivity of natural language understanding models to word-order perturbations have shown that the state-of-the-art models in several language tasks may have a unique way to understand the text that could seldom be explained with conventional syntax and semantics. In this paper, we investigate the insensitivity of natural language models to word-order by quantifying perturbations and analysing their effect on neural models' performance on language understanding tasks in GLUE benchmark. Towards that end, we propose two metrics - the Direct Neighbour Displacement (DND) and the Index Displacement Count (IDC) - that score the local and global ordering of tokens in the perturbed texts and observe that perturbation functions found in prior literature affect only the global ordering while the local ordering remains relatively unperturbed. We propose perturbations at the granularity of sub-words and characters to study the correlation between DND, IDC and the performance of neural language models on natural language tasks. We find that neural language models - pretrained and non-pretrained Transformers, LSTMs, and Convolutional architectures - require local ordering more so than the global ordering of tokens. The proposed metrics and the suite of perturbations allow a systematic way to study the (in)sensitivity of neural language understanding models to varying degree of perturbations.
MLMLM: Link Prediction with Mean Likelihood Masked Language Model
Sep 15, 2020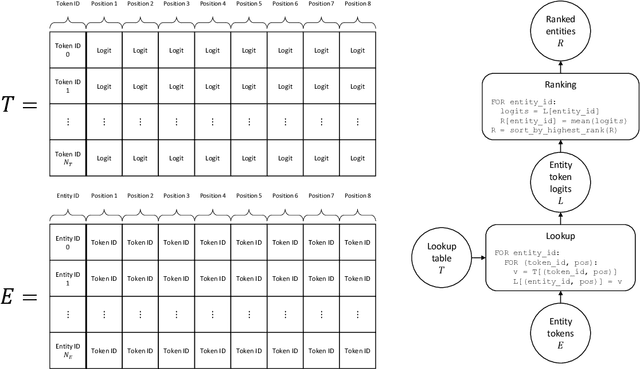
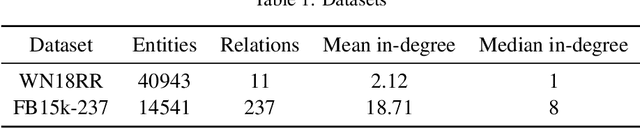
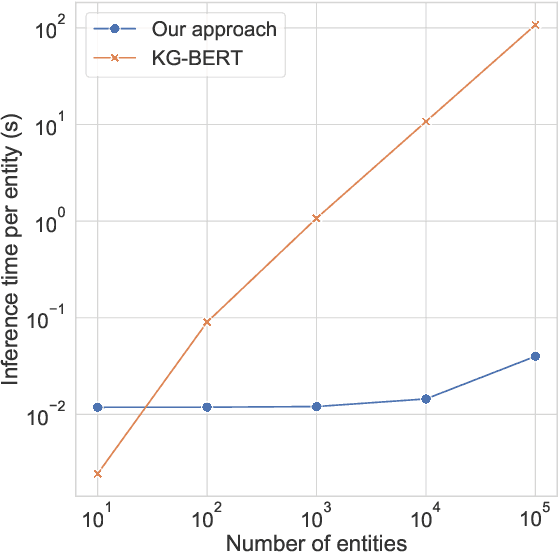
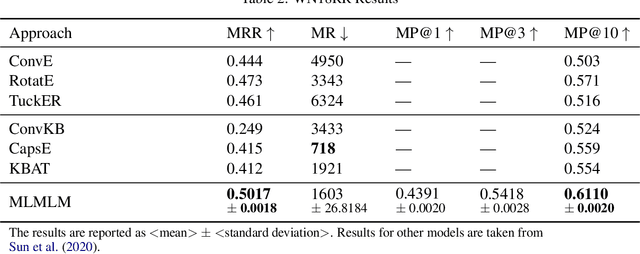
Knowledge Bases (KBs) are easy to query, verifiable, and interpretable. They however scale with man-hours and high-quality data. Masked Language Models (MLMs), such as BERT, scale with computing power as well as unstructured raw text data. The knowledge contained within those models is however not directly interpretable. We propose to perform link prediction with MLMs to address both the KBs scalability issues and the MLMs interpretability issues. To do that we introduce MLMLM, Mean Likelihood Masked Language Model, an approach comparing the mean likelihood of generating the different entities to perform link prediction in a tractable manner. We obtain State of the Art (SotA) results on the WN18RR dataset and the best non-entity-embedding based results on the FB15k-237 dataset. We also obtain convincing results on link prediction on previously unseen entities, making MLMLM a suitable approach to introducing new entities to a KB.