 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeecpc: An R-package for generic co-data models for high-dimensional prediction
May 16, 2022



High-dimensional prediction considers data with more variables than samples. Generic research goals are to find the best predictor or to select variables. Results may be improved by exploiting prior information in the form of co-data, providing complementary data not on the samples, but on the variables. We consider adaptive ridge penalised generalised linear and Cox models, in which the variable specific ridge penalties are adapted to the co-data to give a priori more weight to more important variables. The R-package ecpc originally accommodated various and possibly multiple co-data sources, including categorical co-data, i.e. groups of variables, and continuous co-data. Continuous co-data, however, was handled by adaptive discretisation, potentially inefficiently modelling and losing information. Here, we present an extension to the method and software for generic co-data models, particularly for continuous co-data. At the basis lies a classical linear regression model, regressing prior variance weights on the co-data. Co-data variables are then estimated with empirical Bayes moment estimation. After placing the estimation procedure in the classical regression framework, extension to generalised additive and shape constrained co-data models is straightforward. Besides, we show how ridge penalties may be transformed to elastic net penalties with the R-package squeezy. In simulation studies we first compare various co-data models for continuous co-data from the extension to the original method. Secondly, we compare variable selection performance to other variable selection methods. Moreover, we demonstrate use of the package in several examples throughout the paper.
Flexible co-data learning for high-dimensional prediction
May 08, 2020

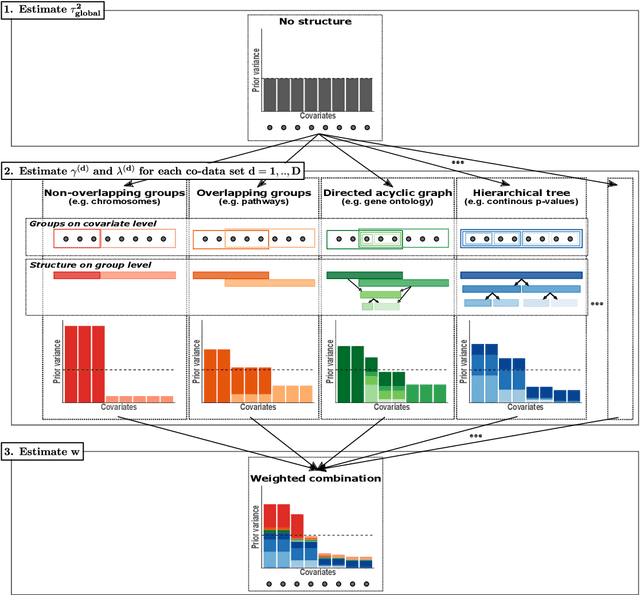

Clinical research often focuses on complex traits in which many variables play a role in mechanisms driving, or curing, diseases. Clinical prediction is hard when data is high-dimensional, but additional information, like domain knowledge and previously published studies, may be helpful to improve predictions. Such complementary data, or co-data, provide information on the covariates, such as genomic location or p-values from external studies. Our method enables exploiting multiple and various co-data sources to improve predictions. We use discrete or continuous co-data to define possibly overlapping or hierarchically structured groups of covariates. These are then used to estimate adaptive multi-group ridge penalties for generalised linear and Cox models. We combine empirical Bayes estimation of group penalty hyperparameters with an extra level of shrinkage. This renders a uniquely flexible framework as any type of shrinkage can be used on the group level. The hyperparameter shrinkage learns how relevant a specific co-data source is, counters overfitting of hyperparameters for many groups, and accounts for structured co-data. We describe various types of co-data and propose suitable forms of hypershrinkage. The method is very versatile, as it allows for integration and weighting of multiple co-data sets, inclusion of unpenalised covariates and posterior variable selection. We demonstrate it on two cancer genomics applications and show that it may improve the performance of other dense and parsimonious prognostic models substantially, and stabilises variable selection.