 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Segmentation of LiDAR Sequences: Dataset and Algorithm
Jun 16, 2022
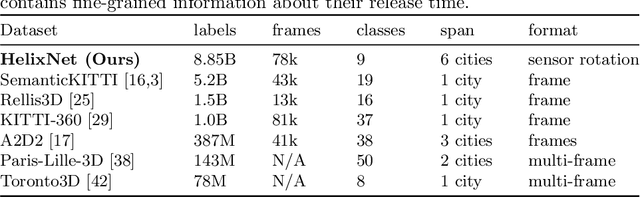
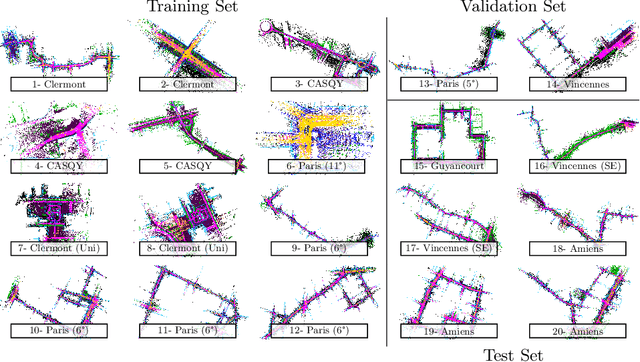
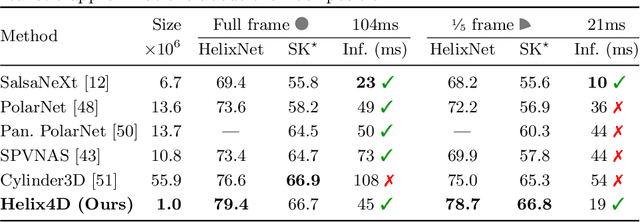
Roof-mounted spinning LiDAR sensors are widely used by autonomous vehicles, driving the need for real-time processing of 3D point sequences. However, most LiDAR semantic segmentation datasets and algorithms split these acquisitions into $360^\circ$ frames, leading to acquisition latency that is incompatible with realistic real-time applications and evaluations. We address this issue with two key contributions. First, we introduce HelixNet, a $10$ billion point dataset with fine-grained labels, timestamps, and sensor rotation information that allows an accurate assessment of real-time readiness of segmentation algorithms. Second, we propose Helix4D, a compact and efficient spatio-temporal transformer architecture specifically designed for rotating LiDAR point sequences. Helix4D operates on acquisition slices that correspond to a fraction of a full rotation of the sensor, significantly reducing the total latency. We present an extensive benchmark of the performance and real-time readiness of several state-of-the-art models on HelixNet and SemanticKITTI. Helix4D reaches accuracy on par with the best segmentation algorithms with a reduction of more than $5\times$ in terms of latency and $50\times$ in model size. Code and data are available at: https://romainloiseau.fr/helixnet
Representing Shape Collections with Alignment-Aware Linear Models
Sep 03, 2021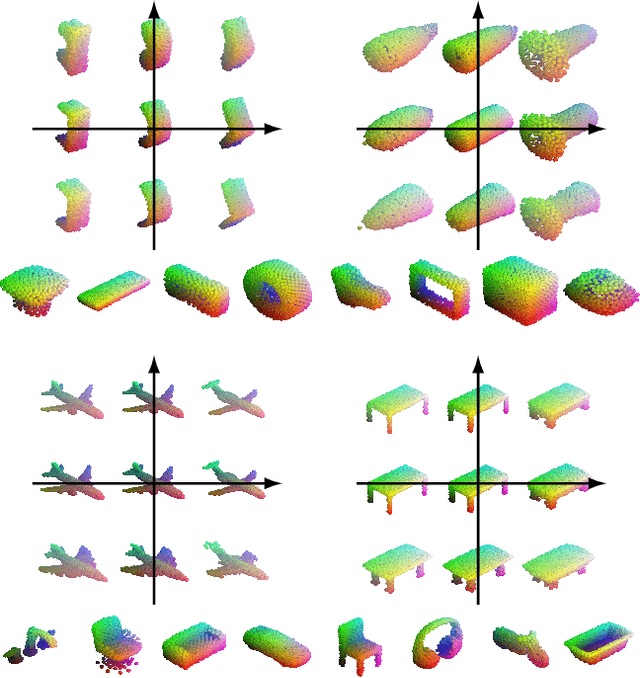
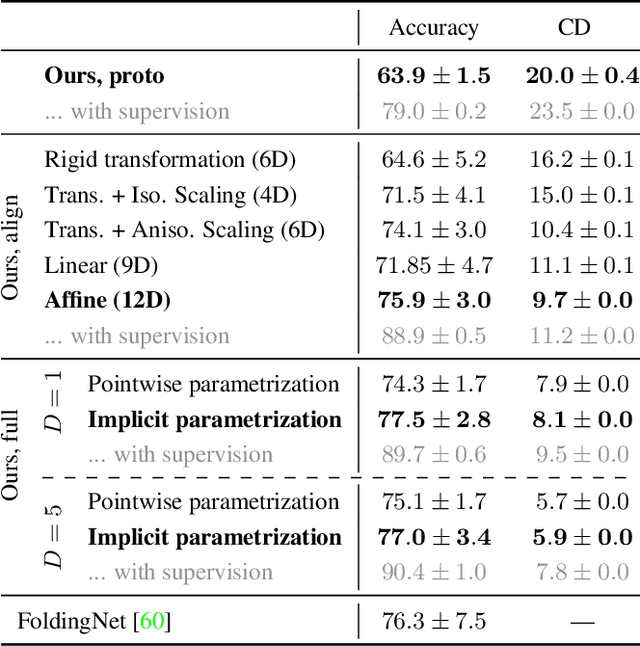


In this paper, we revisit the classical representation of 3D point clouds as linear shape models. Our key insight is to leverage deep learning to represent a collection of shapes as affine transformations of low-dimensional linear shape models. Each linear model is characterized by a shape prototype, a low-dimensional shape basis and two neural networks. The networks take as input a point cloud and predict the coordinates of a shape in the linear basis and the affine transformation which best approximate the input. Both linear models and neural networks are learned end-to-end using a single reconstruction loss. The main advantage of our approach is that, in contrast to many recent deep approaches which learn feature-based complex shape representations, our model is explicit and every operation occurs in 3D space. As a result, our linear shape models can be easily visualized and annotated, and failure cases can be visually understood. While our main goal is to introduce a compact and interpretable representation of shape collections, we show it leads to state of the art results for few-shot segmentation.