 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Structured Adversarial Attacks Using Frank-Wolfe Method
Feb 15, 2021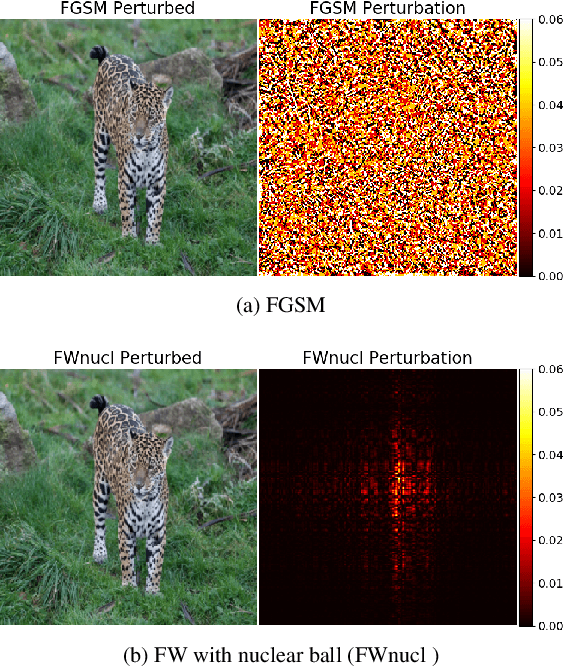


White box adversarial perturbations are generated via iterative optimization algorithms most often by minimizing an adversarial loss on a $\ell_p$ neighborhood of the original image, the so-called distortion set. Constraining the adversarial search with different norms results in disparately structured adversarial examples. Here we explore several distortion sets with structure-enhancing algorithms. These new structures for adversarial examples might provide challenges for provable and empirical robust mechanisms. Because adversarial robustness is still an empirical field, defense mechanisms should also reasonably be evaluated against differently structured attacks. Besides, these structured adversarial perturbations may allow for larger distortions size than their $\ell_p$ counter-part while remaining imperceptible or perceptible as natural distortions of the image. We will demonstrate in this work that the proposed structured adversarial examples can significantly bring down the classification accuracy of adversarialy trained classifiers while showing low $\ell_2$ distortion rate. For instance, on ImagNet dataset the structured attacks drop the accuracy of adversarial model to near zero with only 50\% of $\ell_2$ distortion generated using white-box attacks like PGD. As a byproduct, our finding on structured adversarial examples can be used for adversarial regularization of models to make models more robust or improve their generalization performance on datasets which are structurally different.