 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Neural Input Search for Recommender Systems
Jun 08, 2020

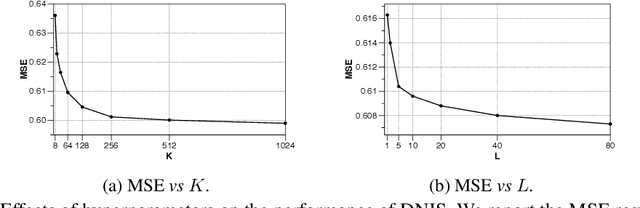
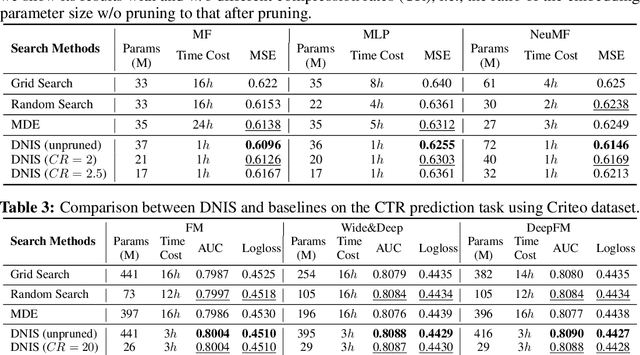
Latent factor models are the driving forces of the state-of-the-art recommender systems, with an important insight of vectorizing raw input features into dense embeddings. The dimensions of different feature embeddings are often set to a uniform value manually or through grid search, which may yield suboptimal model performance. Existing work applied heuristic methods or reinforcement learning to search for varying embedding dimensions. However, the embedding dimension per feature is rigidly chosen from a restricted set of candidates due to the scalability issue involved in the optimization process over a large search space. In this paper, we propose a differentiable neural input search algorithm towards learning more flexible dimensions of feature embeddings, namely a mixed dimension scheme, leading to better recommendation performance and lower memory cost. Our method can be seamlessly incorporated with various existing architectures of latent factor models for recommendation. We conduct experiments with 6 state-of-the-art model architectures on two typical recommendation tasks: Collaborative Filtering (CF) and Click-Through-Rate (CTR) prediction. The results demonstrate that our method achieves the best recommendation performance compared with 3 neural input search approaches over all the model architectures, and can reduce the number of embedding parameters by 2x and 20x on CF and CTR prediction, respectively.
Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions
Sep 07, 2019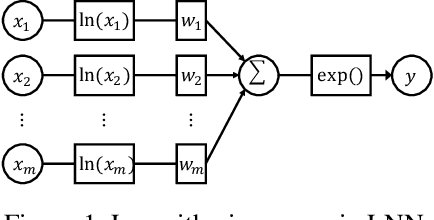
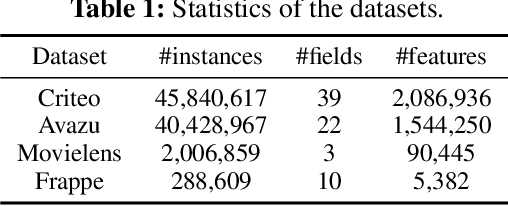
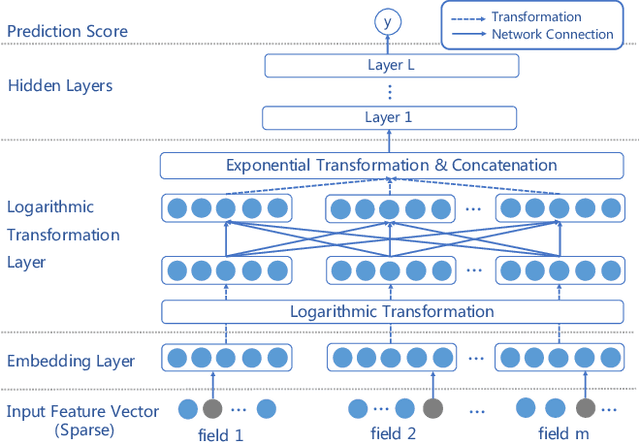
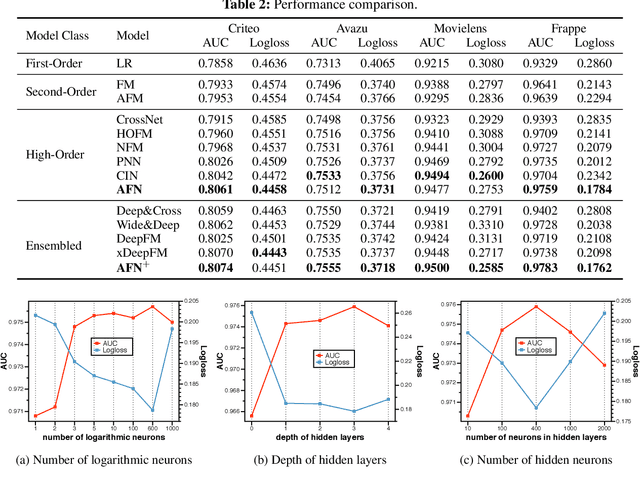
Various factorization-based methods have been proposed to leverage second-order, or higher-order cross features for boosting the performance of predictive models. They generally enumerate all the cross features under a predefined maximum order, and then identify useful feature interactions through model training, which suffer from two drawbacks. First, they have to make a trade-off between the expressiveness of higher-order cross features and the computational cost, resulting in suboptimal predictions. Second, enumerating all the cross features, including irrelevant ones, may introduce noisy feature combinations that degrade model performance. In this work, we propose the Adaptive Factorization Network (AFN), a new model that learns arbitrary-order cross features adaptively from data. The core of AFN is a logarithmic transformation layer to convert the power of each feature in a feature combination into the coefficient to be learned. The experimental results on four real datasets demonstrate the superior predictive performance of AFN against the start-of-the-arts.
Revisiting Flow Information for Traffic Prediction
Jun 03, 2019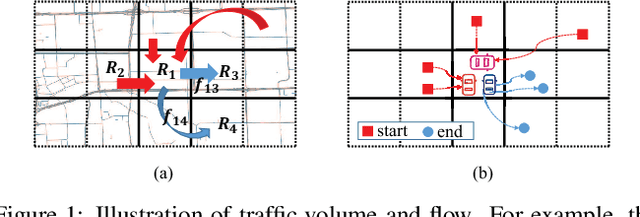
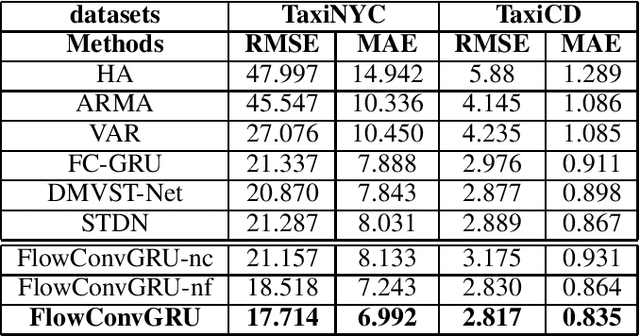
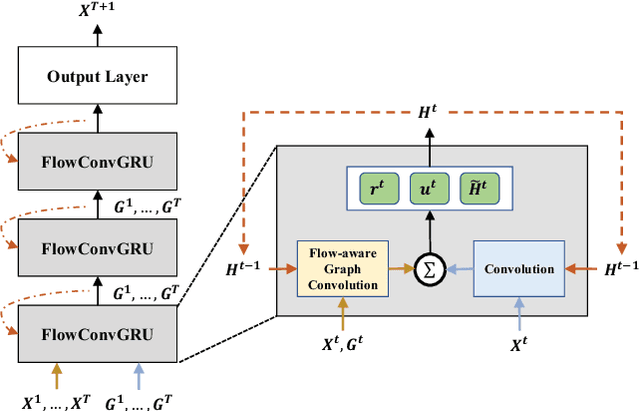
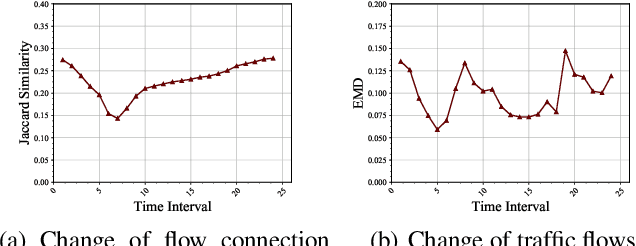
Traffic prediction is a fundamental task in many real applications, which aims to predict the future traffic volume in any region of a city. In essence, traffic volume in a region is the aggregation of traffic flows from/to the region. However, existing traffic prediction methods focus on modeling complex spatiotemporal traffic correlations and seldomly study the influence of the original traffic flows among regions. In this paper, we revisit the traffic flow information and exploit the direct flow correlations among regions towards more accurate traffic prediction. We introduce a novel flow-aware graph convolution to model dynamic flow correlations among regions. We further introduce an integrated Gated Recurrent Unit network to incorporate flow correlations with spatiotemporal modeling. The experimental results on real-world traffic datasets validate the effectiveness of the proposed method, especially on the traffic conditions with a great change on flows.
Explaining Latent Factor Models for Recommendation with Influence Functions
Nov 20, 2018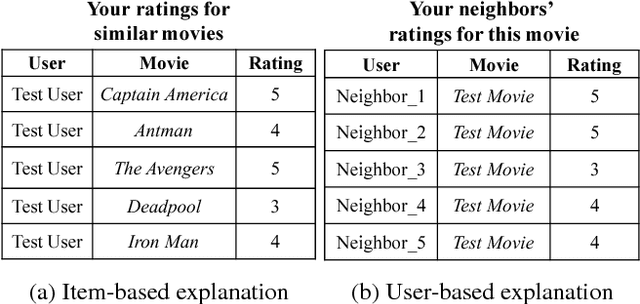

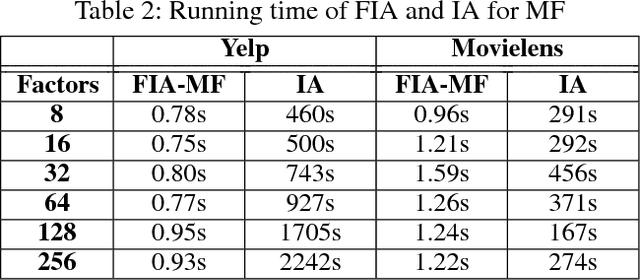
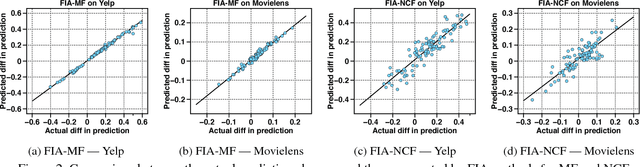
Latent factor models (LFMs) such as matrix factorization achieve the state-of-the-art performance among various Collaborative Filtering (CF) approaches for recommendation. Despite the high recommendation accuracy of LFMs, a critical issue to be resolved is the lack of explainability. Extensive efforts have been made in the literature to incorporate explainability into LFMs. However, they either rely on auxiliary information which may not be available in practice, or fail to provide easy-to-understand explanations. In this paper, we propose a fast influence analysis method named FIA, which successfully enforces explicit neighbor-style explanations to LFMs with the technique of influence functions stemmed from robust statistics. We first describe how to employ influence functions to LFMs to deliver neighbor-style explanations. Then we develop a novel influence computation algorithm for matrix factorization with high efficiency. We further extend it to the more general neural collaborative filtering and introduce an approximation algorithm to accelerate influence analysis over neural network models. Experimental results on real datasets demonstrate the correctness, efficiency and usefulness of our proposed method.