 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-by-Step Guidance to Differential Anemia Diagnosis with Real-World Data and Deep Reinforcement Learning
Dec 03, 2024Clinical diagnostic guidelines outline the key questions to answer to reach a diagnosis. Inspired by guidelines, we aim to develop a model that learns from electronic health records to determine the optimal sequence of actions for accurate diagnosis. Focusing on anemia and its sub-types, we employ deep reinforcement learning (DRL) algorithms and evaluate their performance on both a synthetic dataset, which is based on expert-defined diagnostic pathways, and a real-world dataset. We investigate the performance of these algorithms across various scenarios. Our experimental results demonstrate that DRL algorithms perform competitively with state-of-the-art methods while offering the significant advantage of progressively generating pathways to the suggested diagnosis, providing a transparent decision-making process that can guide and explain diagnostic reasoning.
Deep Reinforcement Learning for Personalized Diagnostic Decision Pathways Using Electronic Health Records: A Comparative Study on Anemia and Systemic Lupus Erythematosus
Apr 09, 2024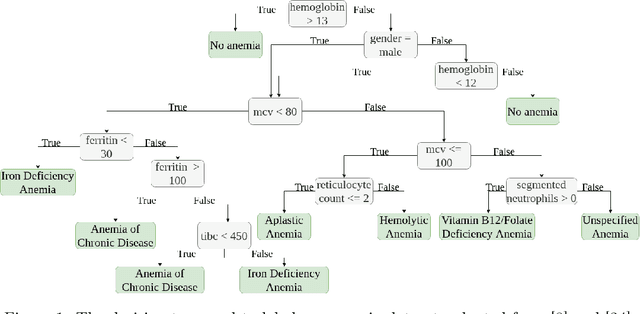

Background: Clinical diagnosis is typically reached by following a series of steps recommended by guidelines authored by colleges of experts. Accordingly, guidelines play a crucial role in rationalizing clinical decisions but suffer from limitations as they are built to cover the majority of the population and fail at covering patients with uncommon conditions. Moreover, their updates are long and expensive, making them unsuitable for emerging diseases and practices. Methods: Inspired by guidelines, we formulate the task of diagnosis as a sequential decision-making problem and study the use of Deep Reinforcement Learning (DRL) algorithms to learn the optimal sequence of actions to perform in order to obtain a correct diagnosis from Electronic Health Records (EHRs). We apply DRL on synthetic, but realistic EHRs and develop two clinical use cases: Anemia diagnosis, where the decision pathways follow the schema of a decision tree; and Systemic Lupus Erythematosus (SLE) diagnosis, which follows a weighted criteria score. We particularly evaluate the robustness of our approaches to noisy and missing data since these frequently occur in EHRs. Results: In both use cases, and in the presence of imperfect data, our best DRL algorithms exhibit competitive performance when compared to the traditional classifiers, with the added advantage that they enable the progressive generation of a pathway to the suggested diagnosis which can both guide and explain the decision-making process. Conclusion: DRL offers the opportunity to learn personalized decision pathways to diagnosis. We illustrate with our two use cases their advantages: they generate step-by-step pathways that are self-explanatory; and their correctness is competitive when compared to state-of-the-art approaches.
Extracting Diagnosis Pathways from Electronic Health Records Using Deep Reinforcement Learning
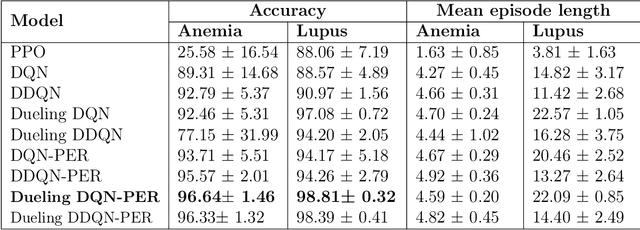
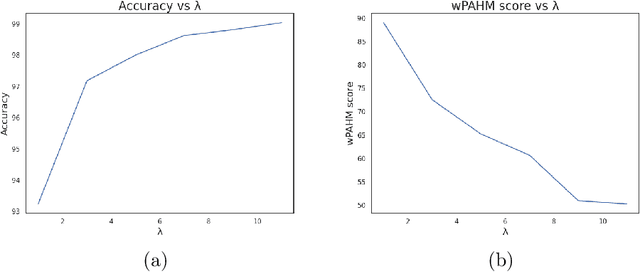
May 10, 2023Clinical diagnosis guidelines aim at specifying the steps that may lead to a diagnosis. Guidelines enable rationalizing and normalizing clinical decisions but suffer drawbacks as they are built to cover the majority of the population and may fail in guiding to the right diagnosis for patients with uncommon conditions or multiple pathologies. Moreover, their updates are long and expensive, making them unsuitable to emerging practices. Inspired by guidelines, we formulate the task of diagnosis as a sequential decision-making problem and study the use of Deep Reinforcement Learning (DRL) algorithms trained on Electronic Health Records (EHRs) to learn the optimal sequence of observations to perform in order to obtain a correct diagnosis. Because of the variety of DRL algorithms and of their sensitivity to the context, we considered several approaches and settings that we compared to each other, and to classical classifiers. We experimented on a synthetic but realistic dataset to differentially diagnose anemia and its subtypes and particularly evaluated the robustness of various approaches to noise and missing data as those are frequent in EHRs. Within the DRL algorithms, Dueling DQN with Prioritized Experience Replay, and Dueling Double DQN with Prioritized Experience Replay show the best and most stable performances. In the presence of imperfect data, the DRL algorithms show competitive, but less stable performances when compared to the classifiers (Random Forest and XGBoost); although they enable the progressive generation of a pathway to the suggested diagnosis, which can both guide or explain the decision process.