 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnapsack Pruning with Inner Distillation
Feb 21, 2020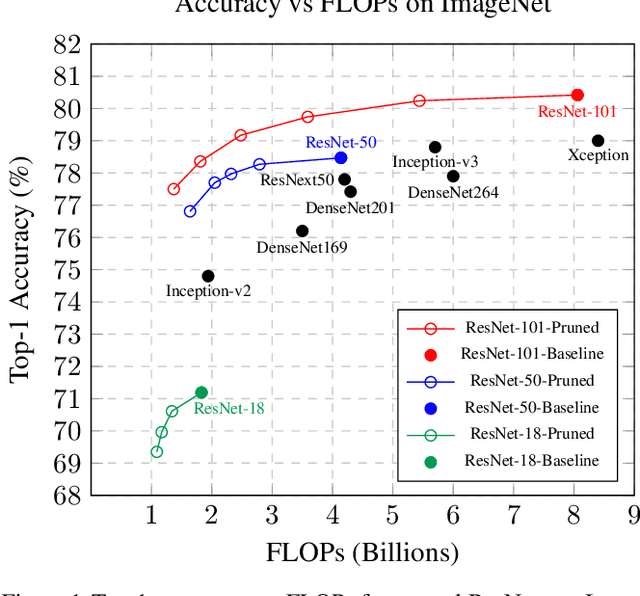
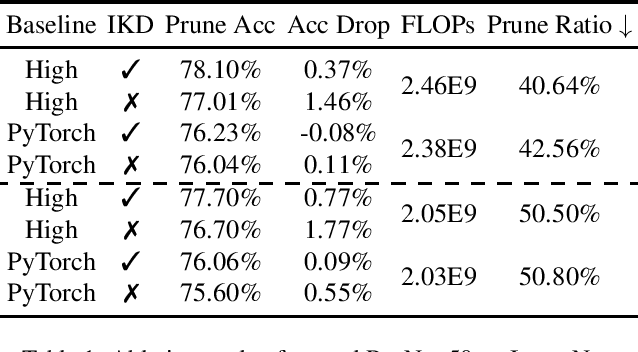
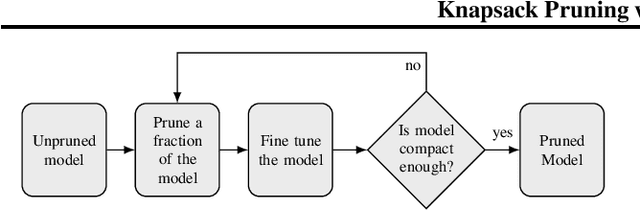
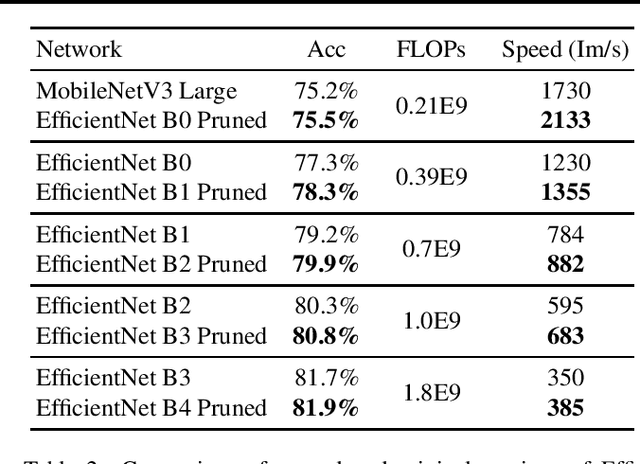
Neural network pruning reduces the computational cost of an over-parameterized network to improve its efficiency. Popular methods vary from $\ell_1$-norm sparsification to Neural Architecture Search (NAS). In this work, we propose a novel pruning method that optimizes the final accuracy of the pruned network and distills knowledge from the over-parameterized parent network's inner layers. To enable this approach, we formulate the network pruning as a Knapsack Problem which optimizes the trade-off between the importance of neurons and their associated computational cost. Then we prune the network channels while maintaining the high-level structure of the network. The pruned network is fine-tuned under the supervision of the parent network using its inner network knowledge, a technique we refer to as the Inner Knowledge Distillation. Our method leads to state-of-the-art pruning results on ImageNet, CIFAR-10 and CIFAR-100 using ResNet backbones. To prune complex network structures such as convolutions with skip-links and depth-wise convolutions, we propose a block grouping approach to cope with these structures. Through this we produce compact architectures with the same FLOPs as EfficientNet-B0 and MobileNetV3 but with higher accuracy, by $1\%$ and $0.3\%$ respectively on ImageNet, and faster runtime on GPU.