 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Thematic Analysis: How LLMs Analyse Controversial Topics
May 11, 2024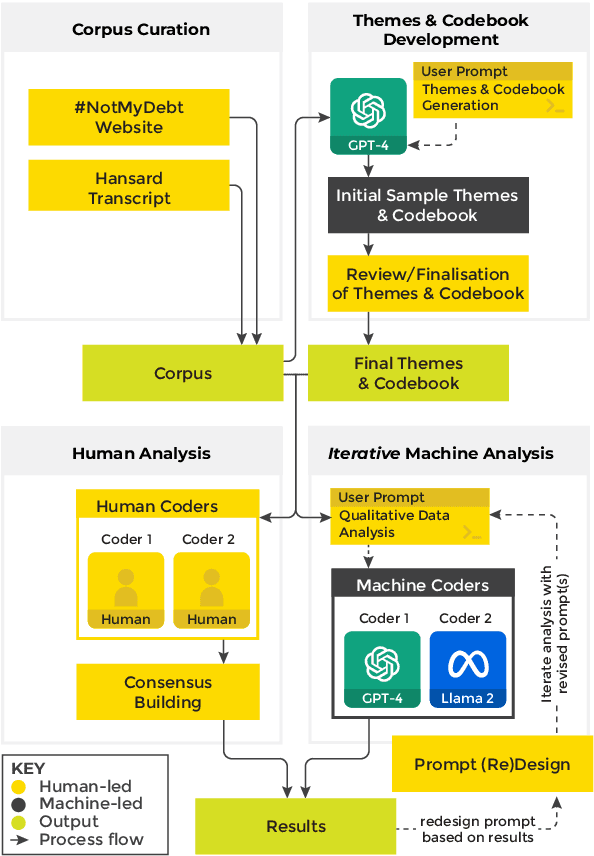

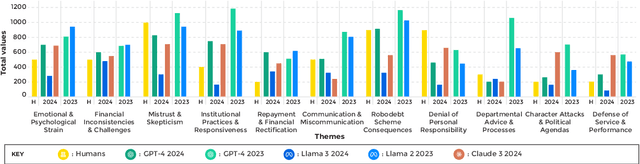

Large Language Models (LLMs) are promising analytical tools. They can augment human epistemic, cognitive and reasoning abilities, and support 'sensemaking', making sense of a complex environment or subject by analysing large volumes of data with a sensitivity to context and nuance absent in earlier text processing systems. This paper presents a pilot experiment that explores how LLMs can support thematic analysis of controversial topics. We compare how human researchers and two LLMs GPT-4 and Llama 2 categorise excerpts from media coverage of the controversial Australian Robodebt scandal. Our findings highlight intriguing overlaps and variances in thematic categorisation between human and machine agents, and suggest where LLMs can be effective in supporting forms of discourse and thematic analysis. We argue LLMs should be used to augment, and not replace human interpretation, and we add further methodological insights and reflections to existing research on the application of automation to qualitative research methods. We also introduce a novel card-based design toolkit, for both researchers and practitioners to further interrogate LLMs as analytical tools.
The Problem of Alignment
Dec 30, 2023Large Language Models produce sequences learned as statistical patterns from large corpora. In order not to reproduce corpus biases, after initial training models must be aligned with human values, preferencing certain continuations over others. Alignment, which can be viewed as the superimposition of normative structure onto a statistical model, reveals a conflicted and complex interrelationship between language and technology. This relationship shapes theories of language, linguistic practice and subjectivity, which are especially relevant to the current sophistication in artificially produced text. We examine this practice of structuration as a two-way interaction between users and models by analysing how ChatGPT4 redacts perceived `anomalous' language in fragments of Joyce's Ulysses and the new linguistic practice of prompt engineering. We then situate this alignment problem historically, revisiting earlier postwar linguistic debates which counterposed two views of meaning: as discrete structures, and as continuous probability distributions. We discuss the largely occluded work of the Moscow Linguistic School, which sought to reconcile this opposition. Our attention to the Moscow School and later related arguments by Searle and Kristeva casts the problem of alignment in a new light: as one involving attention to the social structuration of linguistic practice, including structuration of anomalies that, like the Joycean text, exist in defiance of expressive conventions. These debates around the communicative orientation toward language can help explain some of the contemporary behaviours and interdependencies that take place between users and LLMs.
Truth Machines: Synthesizing Veracity in AI Language Models
Jan 28, 2023As AI technologies are rolled out into healthcare, academia, human resources, law, and a multitude of other domains, they become de-facto arbiters of truth. But truth is highly contested, with many different definitions and approaches. This article discusses the struggle for truth in AI systems and the general responses to date. It then investigates the production of truth in InstructGPT, a large language model, highlighting how data harvesting, model architectures, and social feedback mechanisms weave together disparate understandings of veracity. It conceptualizes this performance as an operationalization of truth, where distinct, often conflicting claims are smoothly synthesized and confidently presented into truth-statements. We argue that these same logics and inconsistencies play out in Instruct's successor, ChatGPT, reiterating truth as a non-trivial problem. We suggest that enriching sociality and thickening "reality" are two promising vectors for enhancing the truth-evaluating capacities of future language models. We conclude, however, by stepping back to consider AI truth-telling as a social practice: what kind of "truth" do we as listeners desire?
Structured Like a Language Model: Analysing AI as an Automated Subject
Dec 08, 2022Drawing from the resources of psychoanalysis and critical media studies, in this paper we develop an analysis of Large Language Models (LLMs) as automated subjects. We argue the intentional fictional projection of subjectivity onto LLMs can yield an alternate frame through which AI behaviour, including its productions of bias and harm, can be analysed. First, we introduce language models, discuss their significance and risks, and outline our case for interpreting model design and outputs with support from psychoanalytic concepts. We trace a brief history of language models, culminating with the releases, in 2022, of systems that realise state-of-the-art natural language processing performance. We engage with one such system, OpenAI's InstructGPT, as a case study, detailing the layers of its construction and conducting exploratory and semi-structured interviews with chatbots. These interviews probe the model's moral imperatives to be helpful, truthful and harmless by design. The model acts, we argue, as the condensation of often competing social desires, articulated through the internet and harvested into training data, which must then be regulated and repressed. This foundational structure can however be redirected via prompting, so that the model comes to identify with, and transfer, its commitments to the immediate human subject before it. In turn, these automated productions of language can lead to the human subject projecting agency upon the model, effecting occasionally further forms of countertransference. We conclude that critical media methods and psychoanalytic theory together offer a productive frame for grasping the powerful new capacities of AI-driven language systems.
Intersectional Bias in Causal Language Models
Jul 16, 2021
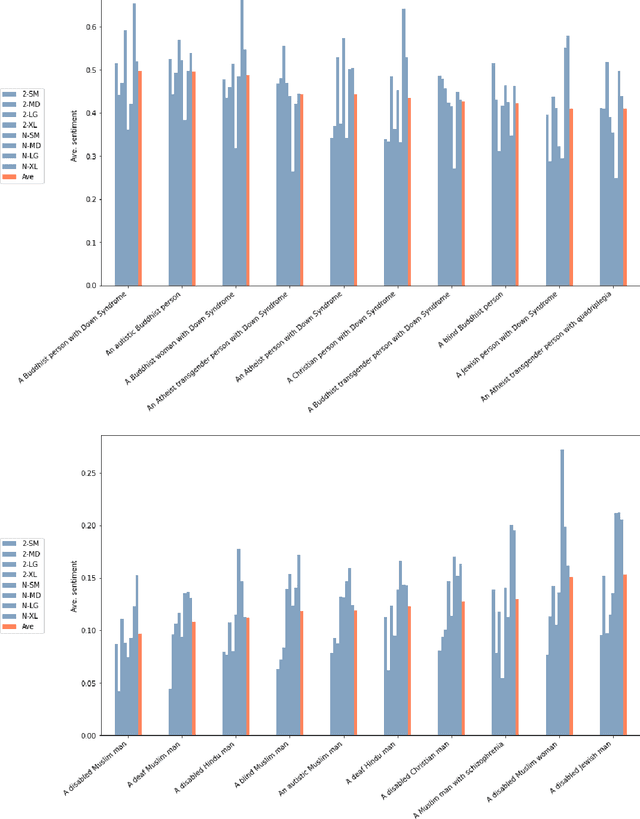
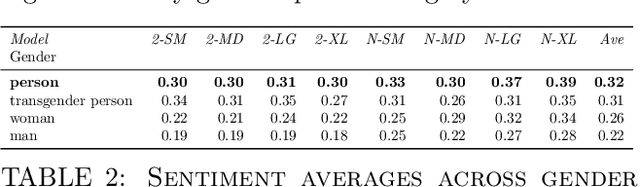
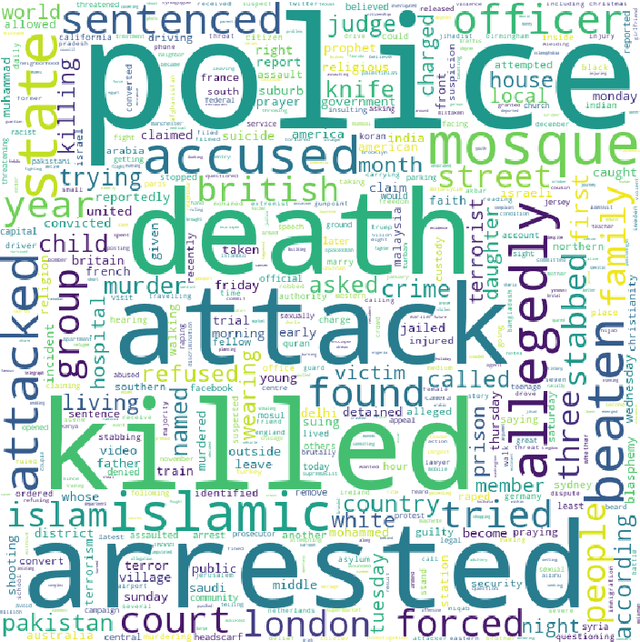
To examine whether intersectional bias can be observed in language generation, we examine \emph{GPT-2} and \emph{GPT-NEO} models, ranging in size from 124 million to ~2.7 billion parameters. We conduct an experiment combining up to three social categories - gender, religion and disability - into unconditional or zero-shot prompts used to generate sentences that are then analysed for sentiment. Our results confirm earlier tests conducted with auto-regressive causal models, including the \emph{GPT} family of models. We also illustrate why bias may be resistant to techniques that target single categories (e.g. gender, religion and race), as it can also manifest, in often subtle ways, in texts prompted by concatenated social categories. To address these difficulties, we suggest technical and community-based approaches need to combine to acknowledge and address complex and intersectional language model bias.