 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Thematic Analysis: How LLMs Analyse Controversial Topics
Paper and Code
May 11, 2024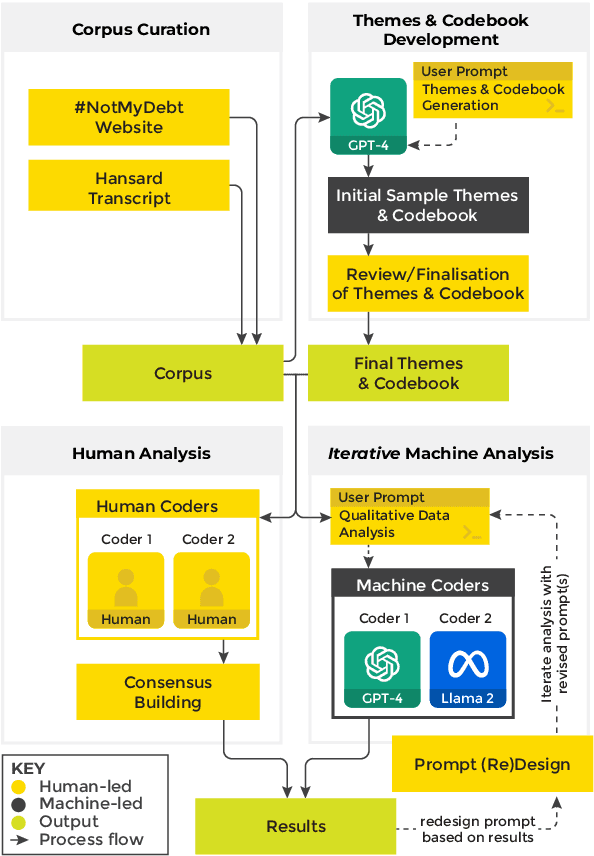

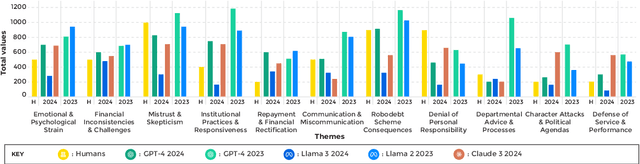

Large Language Models (LLMs) are promising analytical tools. They can augment human epistemic, cognitive and reasoning abilities, and support 'sensemaking', making sense of a complex environment or subject by analysing large volumes of data with a sensitivity to context and nuance absent in earlier text processing systems. This paper presents a pilot experiment that explores how LLMs can support thematic analysis of controversial topics. We compare how human researchers and two LLMs GPT-4 and Llama 2 categorise excerpts from media coverage of the controversial Australian Robodebt scandal. Our findings highlight intriguing overlaps and variances in thematic categorisation between human and machine agents, and suggest where LLMs can be effective in supporting forms of discourse and thematic analysis. We argue LLMs should be used to augment, and not replace human interpretation, and we add further methodological insights and reflections to existing research on the application of automation to qualitative research methods. We also introduce a novel card-based design toolkit, for both researchers and practitioners to further interrogate LLMs as analytical tools.