 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Problem of Alignment
Dec 30, 2023Large Language Models produce sequences learned as statistical patterns from large corpora. In order not to reproduce corpus biases, after initial training models must be aligned with human values, preferencing certain continuations over others. Alignment, which can be viewed as the superimposition of normative structure onto a statistical model, reveals a conflicted and complex interrelationship between language and technology. This relationship shapes theories of language, linguistic practice and subjectivity, which are especially relevant to the current sophistication in artificially produced text. We examine this practice of structuration as a two-way interaction between users and models by analysing how ChatGPT4 redacts perceived `anomalous' language in fragments of Joyce's Ulysses and the new linguistic practice of prompt engineering. We then situate this alignment problem historically, revisiting earlier postwar linguistic debates which counterposed two views of meaning: as discrete structures, and as continuous probability distributions. We discuss the largely occluded work of the Moscow Linguistic School, which sought to reconcile this opposition. Our attention to the Moscow School and later related arguments by Searle and Kristeva casts the problem of alignment in a new light: as one involving attention to the social structuration of linguistic practice, including structuration of anomalies that, like the Joycean text, exist in defiance of expressive conventions. These debates around the communicative orientation toward language can help explain some of the contemporary behaviours and interdependencies that take place between users and LLMs.
Intersectional Bias in Causal Language Models
Jul 16, 2021
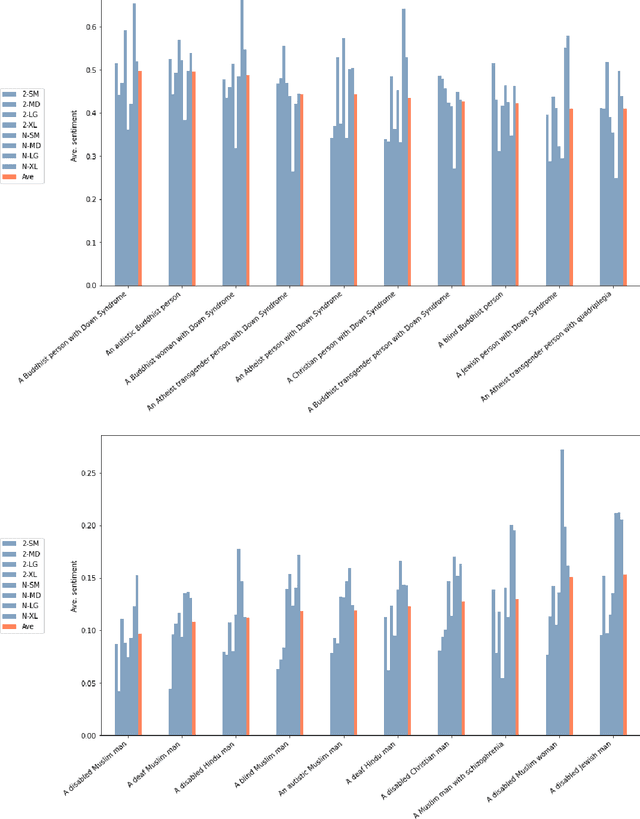
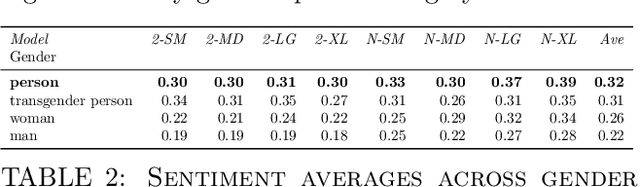
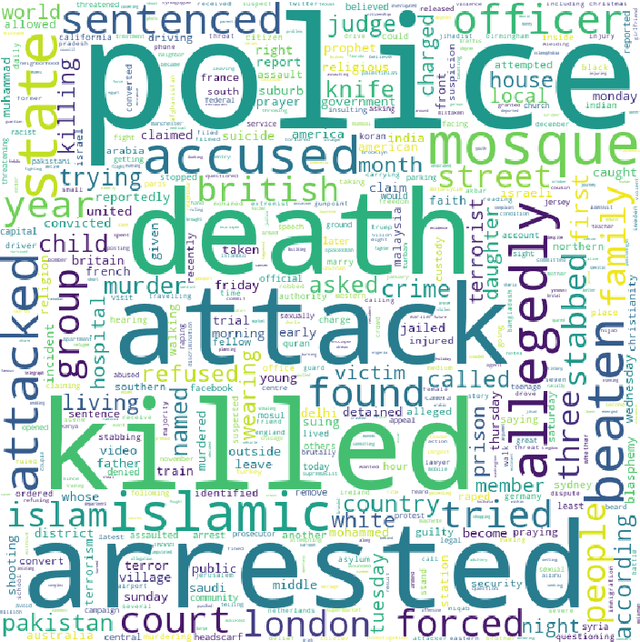
To examine whether intersectional bias can be observed in language generation, we examine \emph{GPT-2} and \emph{GPT-NEO} models, ranging in size from 124 million to ~2.7 billion parameters. We conduct an experiment combining up to three social categories - gender, religion and disability - into unconditional or zero-shot prompts used to generate sentences that are then analysed for sentiment. Our results confirm earlier tests conducted with auto-regressive causal models, including the \emph{GPT} family of models. We also illustrate why bias may be resistant to techniques that target single categories (e.g. gender, religion and race), as it can also manifest, in often subtle ways, in texts prompted by concatenated social categories. To address these difficulties, we suggest technical and community-based approaches need to combine to acknowledge and address complex and intersectional language model bias.