 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarization Based on Video-text Modelling
Jan 10, 2022
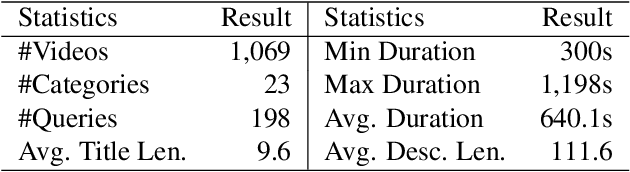
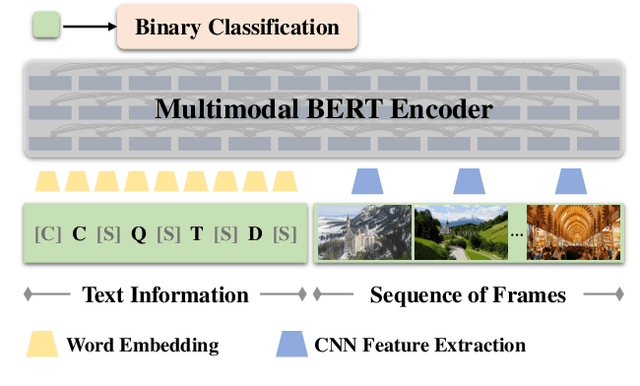
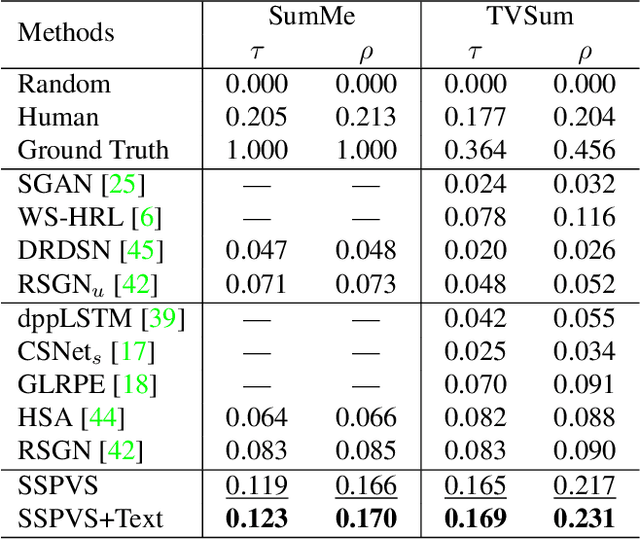
Modern video summarization methods are based on deep neural networks which require a large amount of annotated data for training. However, existing datasets for video summarization are small-scale, easily leading to over-fitting of the deep models. Considering that the annotation of large-scale datasets is time-consuming, we propose a multimodal self-supervised learning framework to obtain semantic representations of videos, which benefits the video summarization task. Specifically, we explore the semantic consistency between the visual information and text information of videos, for the self-supervised pretraining of a multimodal encoder on a newly-collected dataset of video-text pairs. Additionally, we introduce a progressive video summarization method, where the important content in a video is pinpointed progressively to generate better summaries. Finally, an objective evaluation framework is proposed to measure the quality of video summaries based on video classification. Extensive experiments have proved the effectiveness and superiority of our method in rank correlation coefficients, F-score, and the proposed objective evaluation compared to the state of the art.
Video Joint Modelling Based on Hierarchical Transformer for Co-summarization
Dec 27, 2021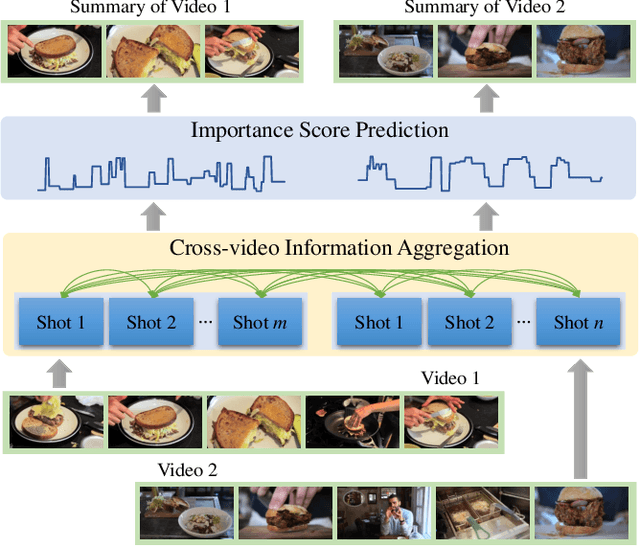

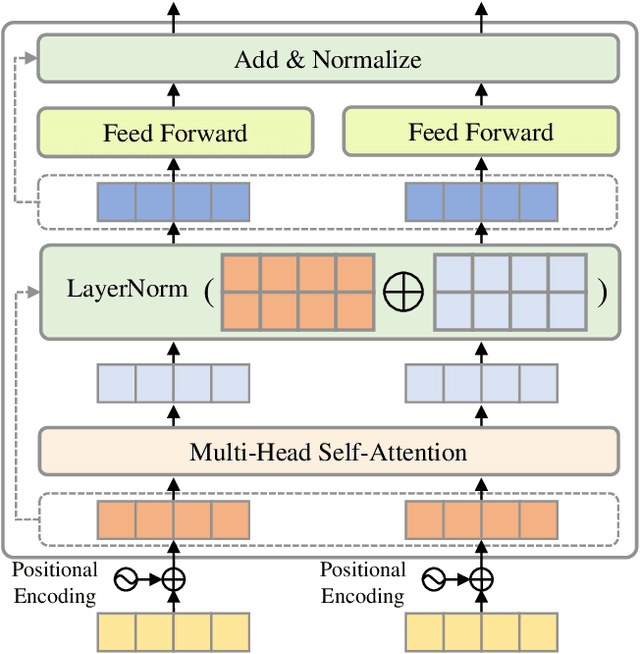
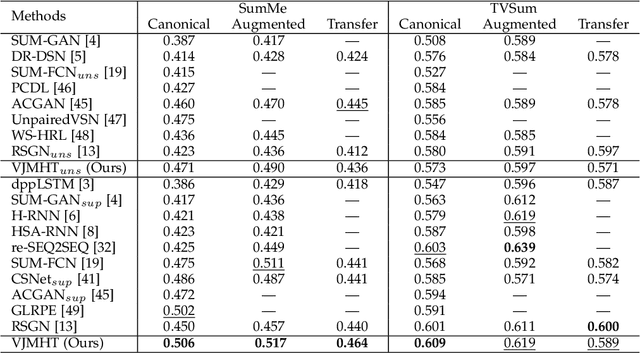
Video summarization aims to automatically generate a summary (storyboard or video skim) of a video, which can facilitate large-scale video retrieving and browsing. Most of the existing methods perform video summarization on individual videos, which neglects the correlations among similar videos. Such correlations, however, are also informative for video understanding and video summarization. To address this limitation, we propose Video Joint Modelling based on Hierarchical Transformer (VJMHT) for co-summarization, which takes into consideration the semantic dependencies across videos. Specifically, VJMHT consists of two layers of Transformer: the first layer extracts semantic representation from individual shots of similar videos, while the second layer performs shot-level video joint modelling to aggregate cross-video semantic information. By this means, complete cross-video high-level patterns are explicitly modelled and learned for the summarization of individual videos. Moreover, Transformer-based video representation reconstruction is introduced to maximize the high-level similarity between the summary and the original video. Extensive experiments are conducted to verify the effectiveness of the proposed modules and the superiority of VJMHT in terms of F-measure and rank-based evaluation.
Precondition and Effect Reasoning for Action Recognition
Dec 19, 2021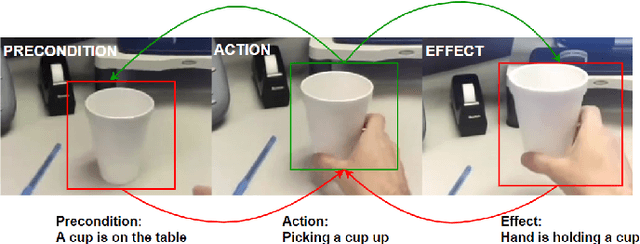



Human action recognition has drawn a lot of attention in the recent years due to the research and application significance. Most existing works on action recognition focus on learning effective spatial-temporal features from videos, but neglect the strong causal relationship among the precondition, action and effect. Such relationships are also crucial to the accuracy of action recognition. In this paper, we propose to model the causal relationships based on the precondition and effect to improve the performance of action recognition. Specifically, a Cycle-Reasoning model is proposed to capture the causal relationships for action recognition. To this end, we annotate precondition and effect for a large-scale action dataset. Experimental results show that the proposed Cycle-Reasoning model can effectively reason about the precondition and effect and can enhance action recognition performance.