 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Joint Modelling Based on Hierarchical Transformer for Co-summarization
Paper and Code
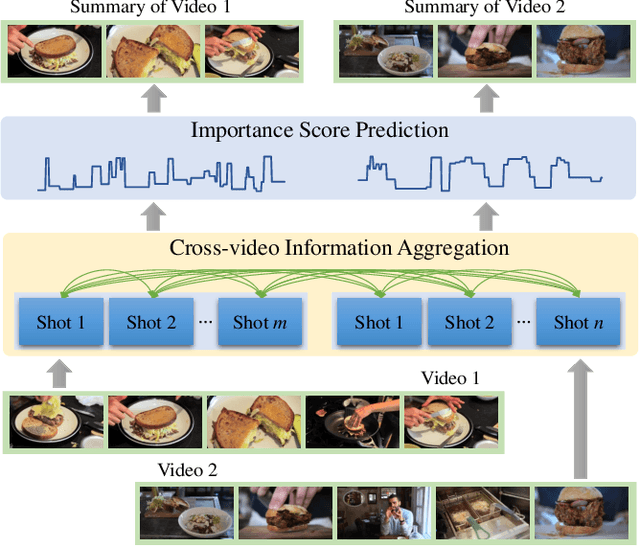

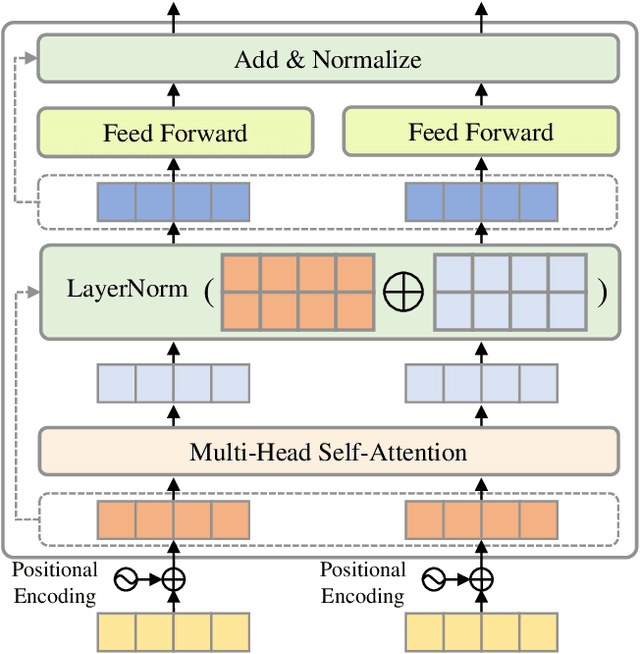
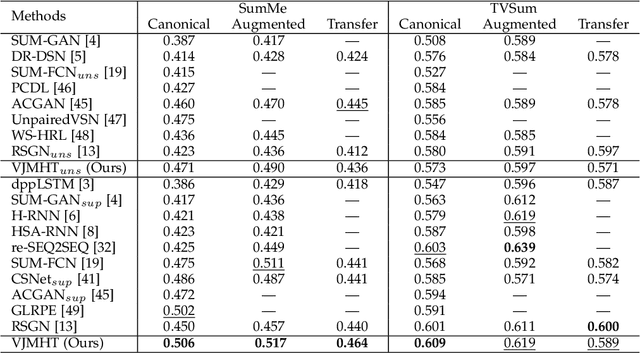
Video summarization aims to automatically generate a summary (storyboard or video skim) of a video, which can facilitate large-scale video retrieving and browsing. Most of the existing methods perform video summarization on individual videos, which neglects the correlations among similar videos. Such correlations, however, are also informative for video understanding and video summarization. To address this limitation, we propose Video Joint Modelling based on Hierarchical Transformer (VJMHT) for co-summarization, which takes into consideration the semantic dependencies across videos. Specifically, VJMHT consists of two layers of Transformer: the first layer extracts semantic representation from individual shots of similar videos, while the second layer performs shot-level video joint modelling to aggregate cross-video semantic information. By this means, complete cross-video high-level patterns are explicitly modelled and learned for the summarization of individual videos. Moreover, Transformer-based video representation reconstruction is introduced to maximize the high-level similarity between the summary and the original video. Extensive experiments are conducted to verify the effectiveness of the proposed modules and the superiority of VJMHT in terms of F-measure and rank-based evaluation.