 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarization Based on Video-text Modelling
Paper and Code
Jan 10, 2022
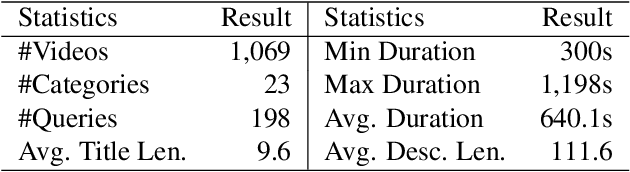
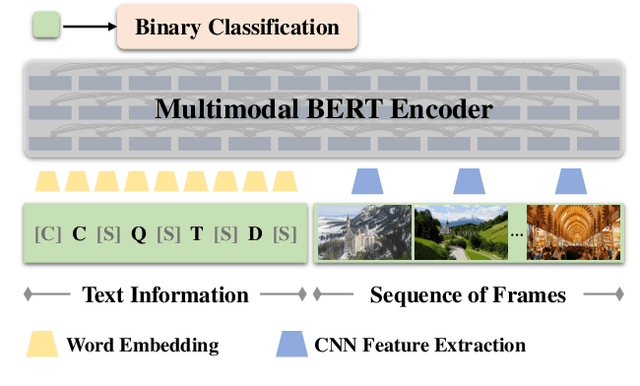
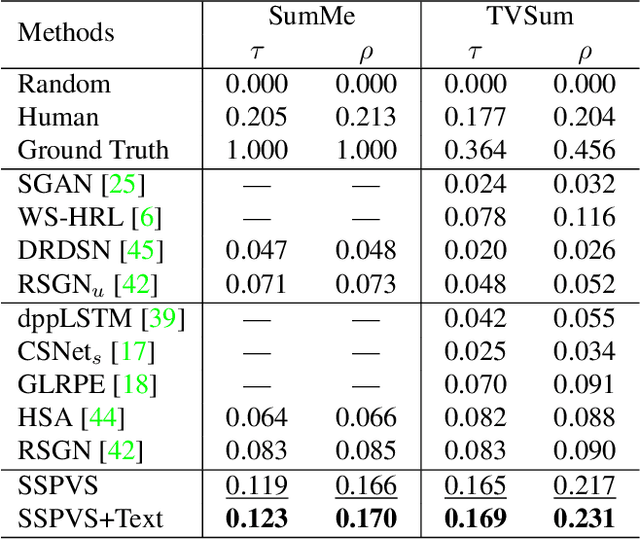
Modern video summarization methods are based on deep neural networks which require a large amount of annotated data for training. However, existing datasets for video summarization are small-scale, easily leading to over-fitting of the deep models. Considering that the annotation of large-scale datasets is time-consuming, we propose a multimodal self-supervised learning framework to obtain semantic representations of videos, which benefits the video summarization task. Specifically, we explore the semantic consistency between the visual information and text information of videos, for the self-supervised pretraining of a multimodal encoder on a newly-collected dataset of video-text pairs. Additionally, we introduce a progressive video summarization method, where the important content in a video is pinpointed progressively to generate better summaries. Finally, an objective evaluation framework is proposed to measure the quality of video summaries based on video classification. Extensive experiments have proved the effectiveness and superiority of our method in rank correlation coefficients, F-score, and the proposed objective evaluation compared to the state of the art.