 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Constrained Dominant Sets for Person Re-identification
Apr 25, 2019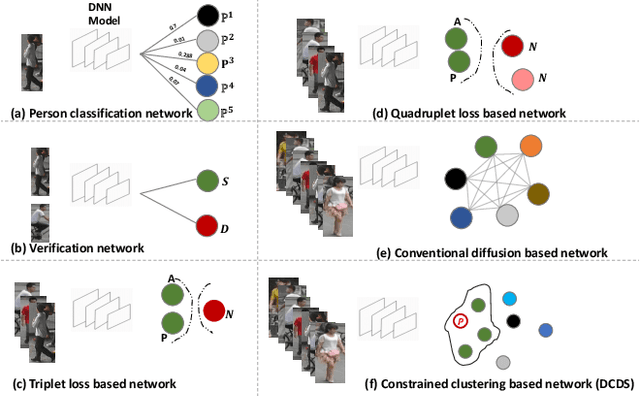
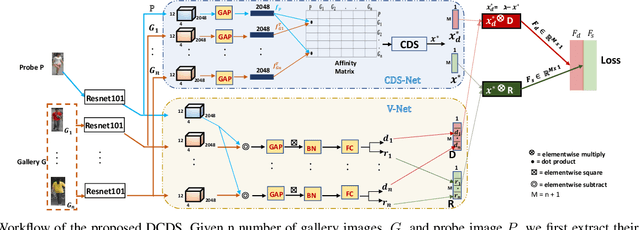

In this work, we propose an end-to-end constrained clustering scheme to tackle the person re-identification (re-id) problem. Deep neural networks (DNN) have recently proven to be effective on person re-identification task. In particular, rather than leveraging solely a probe-gallery similarity, diffusing the similarities among the gallery images in an end-to-end manner has proven to be effective in yielding a robust probe-gallery affinity. However, existing methods do not apply probe image as a constraint, and are prone to noise propagation during the similarity diffusion process. To overcome this, we propose an intriguing scheme which treats person-image retrieval problem as a {\em constrained clustering optimization} problem, called deep constrained dominant sets (DCDS). Given a probe and gallery images, we re-formulate person re-id problem as finding a constrained cluster, where the probe image is taken as a constraint (seed) and each cluster corresponds to a set of images corresponding to the same person. By optimizing the constrained clustering in an end-to-end manner, we naturally leverage the contextual knowledge of a set of images corresponding to the given person-images. We further enhance the performance by integrating an auxiliary net alongside DCDS, which employs a multi-scale Resnet. To validate the effectiveness of our method we present experiments on several benchmark datasets and show that the proposed method can outperform state-of-the-art methods.
Multi-feature Fusion for Image Retrieval Using Constrained Dominant Sets
Aug 15, 2018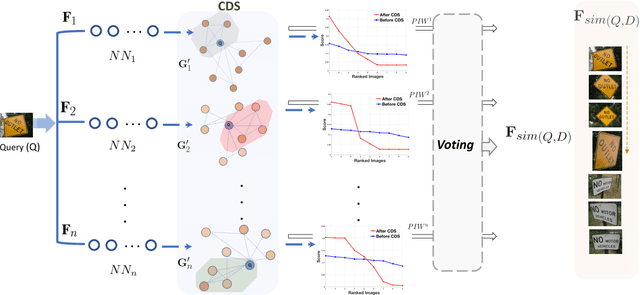
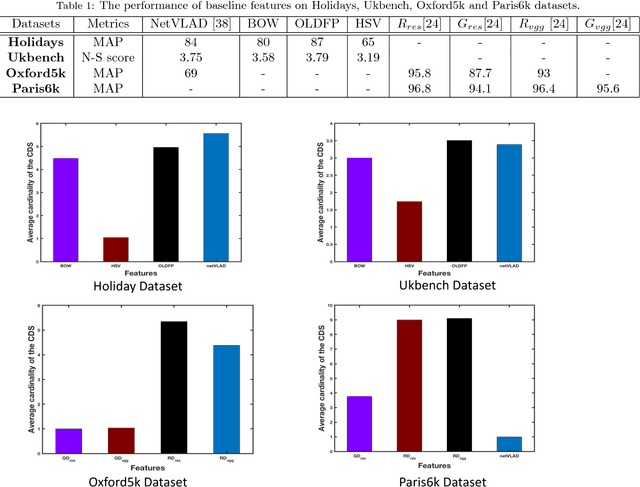
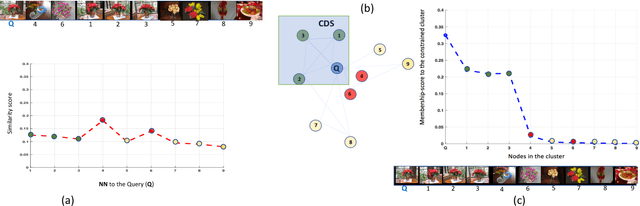
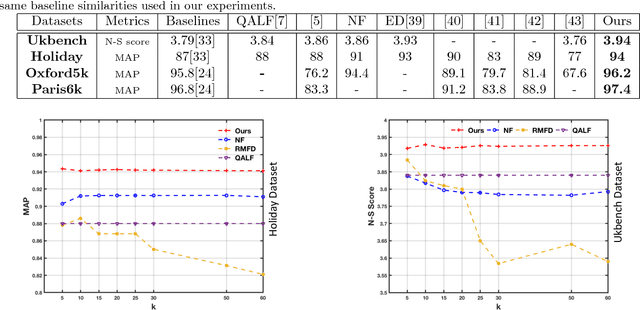
Aggregating different image features for image retrieval has recently shown its effectiveness. While highly effective, though, the question of how to uplift the impact of the best features for a specific query image persists as an open computer vision problem. In this paper, we propose a computationally efficient approach to fuse several hand-crafted and deep features, based on the probabilistic distribution of a given membership score of a constrained cluster in an unsupervised manner. First, we introduce an incremental nearest neighbor (NN) selection method, whereby we dynamically select k-NN to the query. We then build several graphs from the obtained NN sets and employ constrained dominant sets (CDS) on each graph G to assign edge weights which consider the intrinsic manifold structure of the graph, and detect false matches to the query. Finally, we elaborate the computation of feature positive-impact weight (PIW) based on the dispersive degree of the characteristics vector. To this end, we exploit the entropy of a cluster membership-score distribution. In addition, the final NN set bypasses a heuristic voting scheme. Experiments on several retrieval benchmark datasets show that our method can improve the state-of-the-art result.
Dominant Sets for "Constrained" Image Segmentation
Jul 15, 2017
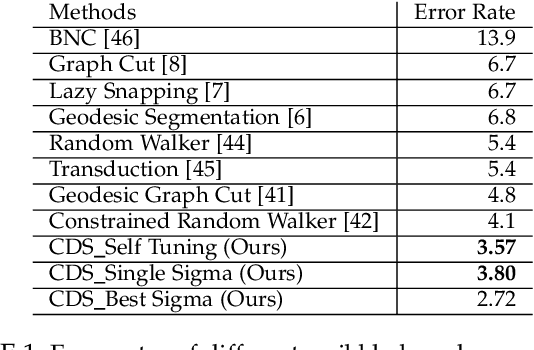

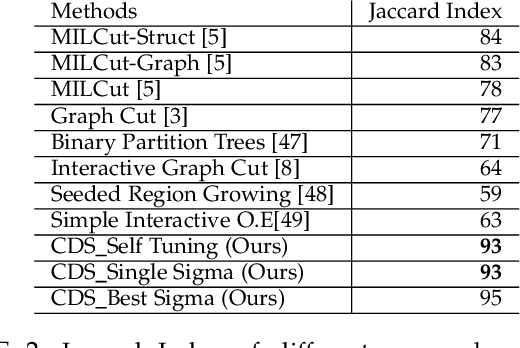
Image segmentation has come a long way since the early days of computer vision, and still remains a challenging task. Modern variations of the classical (purely bottom-up) approach, involve, e.g., some form of user assistance (interactive segmentation) or ask for the simultaneous segmentation of two or more images (co-segmentation). At an abstract level, all these variants can be thought of as "constrained" versions of the original formulation, whereby the segmentation process is guided by some external source of information. In this paper, we propose a new approach to tackle this kind of problems in a unified way. Our work is based on some properties of a family of quadratic optimization problems related to dominant sets, a well-known graph-theoretic notion of a cluster which generalizes the concept of a maximal clique to edge-weighted graphs. In particular, we show that by properly controlling a regularization parameter which determines the structure and the scale of the underlying problem, we are in a position to extract groups of dominant-set clusters that are constrained to contain predefined elements. In particular, we shall focus on interactive segmentation and co-segmentation (in both the unsupervised and the interactive versions). The proposed algorithm can deal naturally with several type of constraints and input modality, including scribbles, sloppy contours, and bounding boxes, and is able to robustly handle noisy annotations on the part of the user. Experiments on standard benchmark datasets show the effectiveness of our approach as compared to state-of-the-art algorithms on a variety of natural images under several input conditions and constraints.