 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-feature Fusion for Image Retrieval Using Constrained Dominant Sets
Paper and Code
Aug 15, 2018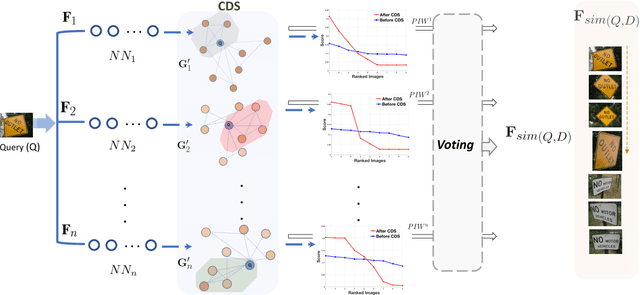
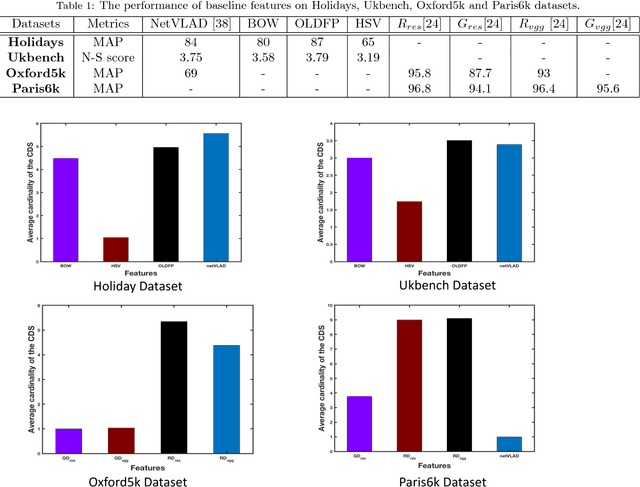
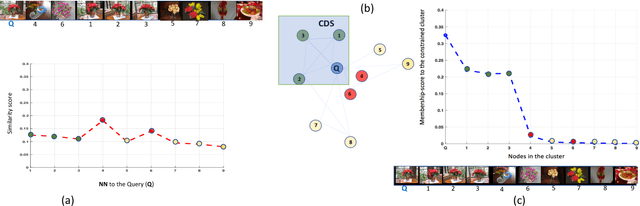
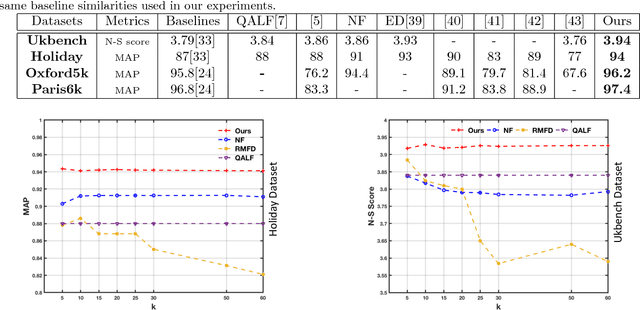
Aggregating different image features for image retrieval has recently shown its effectiveness. While highly effective, though, the question of how to uplift the impact of the best features for a specific query image persists as an open computer vision problem. In this paper, we propose a computationally efficient approach to fuse several hand-crafted and deep features, based on the probabilistic distribution of a given membership score of a constrained cluster in an unsupervised manner. First, we introduce an incremental nearest neighbor (NN) selection method, whereby we dynamically select k-NN to the query. We then build several graphs from the obtained NN sets and employ constrained dominant sets (CDS) on each graph G to assign edge weights which consider the intrinsic manifold structure of the graph, and detect false matches to the query. Finally, we elaborate the computation of feature positive-impact weight (PIW) based on the dispersive degree of the characteristics vector. To this end, we exploit the entropy of a cluster membership-score distribution. In addition, the final NN set bypasses a heuristic voting scheme. Experiments on several retrieval benchmark datasets show that our method can improve the state-of-the-art result.