 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Knowledge Improves Agentic LLM Workflows
Nov 10, 2025Large language models (LLMs) often struggle when performing agentic tasks without substantial tool support, prom-pt engineering, or fine tuning. Despite research showing that domain-dependent, procedural knowledge can dramatically increase planning efficiency, little work evaluates its potential for improving LLM performance on agentic tasks that may require implicit planning. We formalize, implement, and evaluate an agentic LLM workflow that leverages procedural knowledge in the form of a hierarchical task network (HTN). Empirical results of our implementation show that hand-coded HTNs can dramatically improve LLM performance on agentic tasks, and using HTNs can boost a 20b or 70b parameter LLM to outperform a much larger 120b parameter LLM baseline. Furthermore, LLM-created HTNs improve overall performance, though less so. The results suggest that leveraging expertise--from humans, documents, or LLMs--to curate procedural knowledge will become another important tool for improving LLM workflows.
An Approach to Partial Observability in Games: Learning to Both Act and Observe
Aug 11, 2021

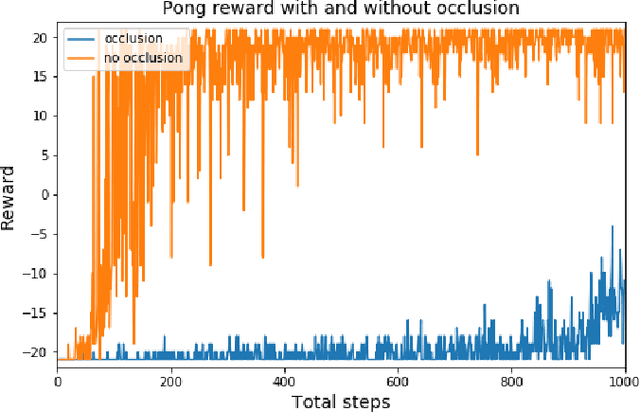

Reinforcement learning (RL) is successful at learning to play games where the entire environment is visible. However, RL approaches are challenged in complex games like Starcraft II and in real-world environments where the entire environment is not visible. In these more complex games with more limited visual information, agents must choose where to look and how to optimally use their limited visual information in order to succeed at the game. We verify that with a relatively simple model the agent can learn where to look in scenarios with a limited visual bandwidth. We develop a method for masking part of the environment in Atari games to force the RL agent to learn both where to look and how to play the game in order to study where the RL agent learns to look. In addition, we develop a neural network architecture and method for allowing the agent to choose where to look and what action to take in the Pong game. Further, we analyze the strategies the agent learns to better understand how the RL agent learns to play the game.
Convolutional Architecture Exploration for Action Recognition and Image Classification
Dec 23, 2015
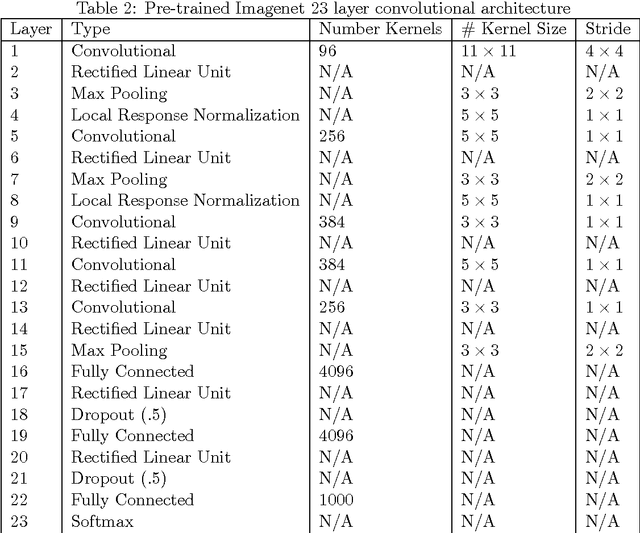


Convolutional Architecture for Fast Feature Encoding (CAFFE) [11] is a software package for the training, classifying, and feature extraction of images. The UCF Sports Action dataset is a widely used machine learning dataset that has 200 videos taken in 720x480 resolution of 9 different sporting activities: diving, golf, swinging, kicking, lifting, horseback riding, running, skateboarding, swinging (various gymnastics), and walking. In this report we report on a caffe feature extraction pipeline of images taken from the videos of the UCF Sports Action dataset. A similar test was performed on overfeat, and results were inferior to caffe. This study is intended to explore the architecture and hyper parameters needed for effective static analysis of action in videos and classification over a variety of image datasets.