 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARCNN: SPAtially Related Convolutional Neural Networks
Aug 24, 2017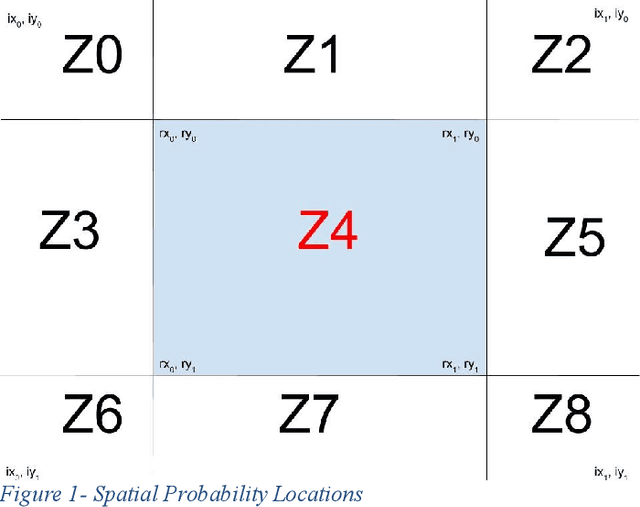


The ability to accurately detect and classify objects at varying pixel sizes in cluttered scenes is crucial to many Navy applications. However, detection performance of existing state-of the-art approaches such as convolutional neural networks (CNNs) degrade and suffer when applied to such cluttered and multi-object detection tasks. We conjecture that spatial relationships between objects in an image could be exploited to significantly improve detection accuracy, an approach that had not yet been considered by any existing techniques (to the best of our knowledge) at the time the research was conducted. We introduce a detection and classification technique called Spatially Related Detection with Convolutional Neural Networks (SPARCNN) that learns and exploits a probabilistic representation of inter-object spatial configurations within images from training sets for more effective region proposals to use with state-of-the-art CNNs. Our empirical evaluation of SPARCNN on the VOC 2007 dataset shows that it increases classification accuracy by 8% when compared to a region proposal technique that does not exploit spatial relations. More importantly, we obtained a higher performance boost of 18.8% when task difficulty in the test set is increased by including highly obscured objects and increased image clutter.
Convolutional Architecture Exploration for Action Recognition and Image Classification
Dec 23, 2015
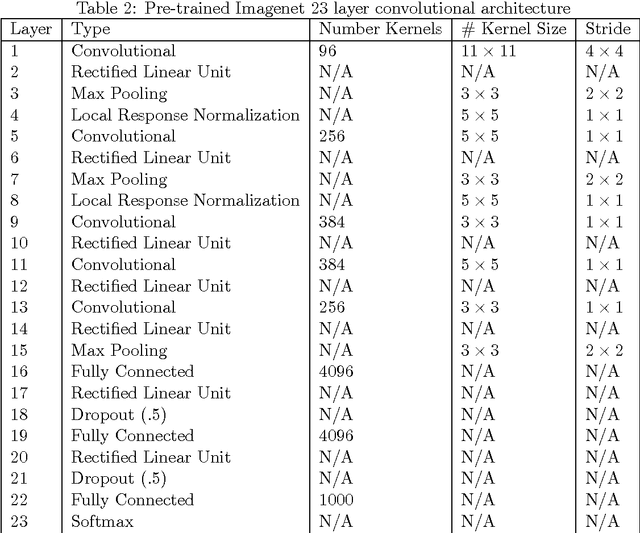


Convolutional Architecture for Fast Feature Encoding (CAFFE) [11] is a software package for the training, classifying, and feature extraction of images. The UCF Sports Action dataset is a widely used machine learning dataset that has 200 videos taken in 720x480 resolution of 9 different sporting activities: diving, golf, swinging, kicking, lifting, horseback riding, running, skateboarding, swinging (various gymnastics), and walking. In this report we report on a caffe feature extraction pipeline of images taken from the videos of the UCF Sports Action dataset. A similar test was performed on overfeat, and results were inferior to caffe. This study is intended to explore the architecture and hyper parameters needed for effective static analysis of action in videos and classification over a variety of image datasets.