 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Partial Observability in Games: Learning to Both Act and Observe
Paper and Code
Aug 11, 2021

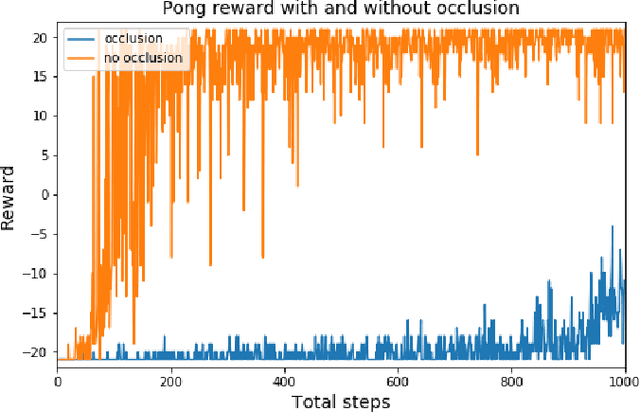

Reinforcement learning (RL) is successful at learning to play games where the entire environment is visible. However, RL approaches are challenged in complex games like Starcraft II and in real-world environments where the entire environment is not visible. In these more complex games with more limited visual information, agents must choose where to look and how to optimally use their limited visual information in order to succeed at the game. We verify that with a relatively simple model the agent can learn where to look in scenarios with a limited visual bandwidth. We develop a method for masking part of the environment in Atari games to force the RL agent to learn both where to look and how to play the game in order to study where the RL agent learns to look. In addition, we develop a neural network architecture and method for allowing the agent to choose where to look and what action to take in the Pong game. Further, we analyze the strategies the agent learns to better understand how the RL agent learns to play the game.