 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithm Configuration Problem
Mar 01, 2024The field of algorithmic optimization has significantly advanced with the development of methods for the automatic configuration of algorithmic parameters. This article delves into the Algorithm Configuration Problem, focused on optimizing parametrized algorithms for solving specific instances of decision/optimization problems. We present a comprehensive framework that not only formalizes the Algorithm Configuration Problem, but also outlines different approaches for its resolution, leveraging machine learning models and heuristic strategies. The article categorizes existing methodologies into per-instance and per-problem approaches, distinguishing between offline and online strategies for model construction and deployment. By synthesizing these approaches, we aim to provide a clear pathway for both understanding and addressing the complexities inherent in algorithm configuration.
Learning to Configure Mathematical Programming Solvers by Mathematical Programming
Jan 10, 2024We discuss the issue of finding a good mathematical programming solver configuration for a particular instance of a given problem, and we propose a two-phase approach to solve it. In the first phase we learn the relationships between the instance, the configuration and the performance of the configured solver on the given instance. A specific difficulty of learning a good solver configuration is that parameter settings may not all be independent; this requires enforcing (hard) constraints, something that many widely used supervised learning methods cannot natively achieve. We tackle this issue in the second phase of our approach, where we use the learnt information to construct and solve an optimization problem having an explicit representation of the dependency/consistency constraints on the configuration parameter settings. We discuss computational results for two different instantiations of this approach on a unit commitment problem arising in the short-term planning of hydro valleys. We use logistic regression as the supervised learning methodology and consider CPLEX as the solver of interest.
A learning-based mathematical programming formulation for the automatic configuration of optimization solvers
Jan 08, 2024We propose a methodology, based on machine learning and optimization, for selecting a solver configuration for a given instance. First, we employ a set of solved instances and configurations in order to learn a performance function of the solver. Secondly, we formulate a mixed-integer nonlinear program where the objective/constraints explicitly encode the learnt information, and which we solve, upon the arrival of an unknown instance, to find the best solver configuration for that instance, based on the performance function. The main novelty of our approach lies in the fact that the configuration set search problem is formulated as a mathematical program, which allows us to a) enforce hard dependence and compatibility constraints on the configurations, and b) solve it efficiently with off-the-shelf optimization tools.
Distance Geometry and Data Science
Sep 18, 2019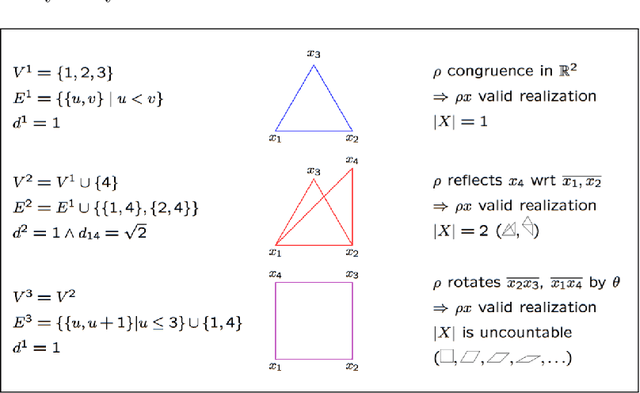



Data are often represented as graphs. Many common tasks in data science are based on distances between entities. While some data science methodologies natively take graphs as their input, there are many more that take their input in vectorial form. In this survey we discuss the fundamental problem of mapping graphs to vectors, and its relation with mathematical programming. We discuss applications, solution methods, dimensional reduction techniques and some of their limits. We then present an application of some of these ideas to neural networks, showing that distance geometry techniques can give competitive performance with respect to more traditional graph-to-vector mappings.
Globally Optimal Symbolic Regression
Nov 15, 2017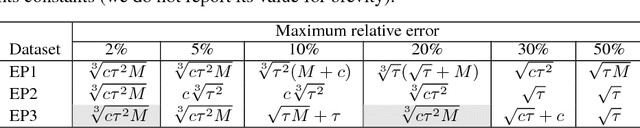
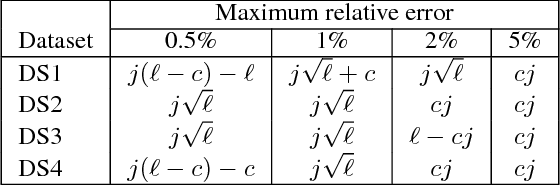
In this study we introduce a new technique for symbolic regression that guarantees global optimality. This is achieved by formulating a mixed integer non-linear program (MINLP) whose solution is a symbolic mathematical expression of minimum complexity that explains the observations. We demonstrate our approach by rediscovering Kepler's law on planetary motion using exoplanet data and Galileo's pendulum periodicity equation using experimental data.