 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Mean Estimation Under User-Level Privacy
Dec 20, 2022We consider the problem of continually releasing an estimate of the population mean of a stream of samples that is user-level differentially private (DP). At each time instant, a user contributes a sample, and the users can arrive in arbitrary order. Until now these requirements of continual release and user-level privacy were considered in isolation. But, in practice, both these requirements come together as the users often contribute data repeatedly and multiple queries are made. We provide an algorithm that outputs a mean estimate at every time instant $t$ such that the overall release is user-level $\varepsilon$-DP and has the following error guarantee: Denoting by $M_t$ the maximum number of samples contributed by a user, as long as $\tilde{\Omega}(1/\varepsilon)$ users have $M_t/2$ samples each, the error at time $t$ is $\tilde{O}(1/\sqrt{t}+\sqrt{M}_t/t\varepsilon)$. This is a universal error guarantee which is valid for all arrival patterns of the users. Furthermore, it (almost) matches the existing lower bounds for the single-release setting at all time instants when users have contributed equal number of samples.
Multiple Support Recovery Using Very Few Measurements Per Sample
May 20, 2021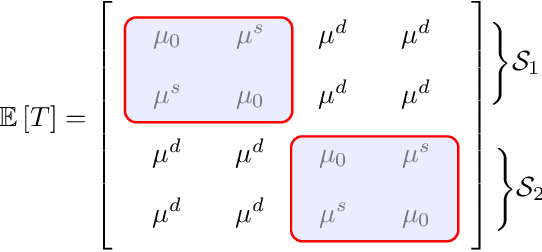
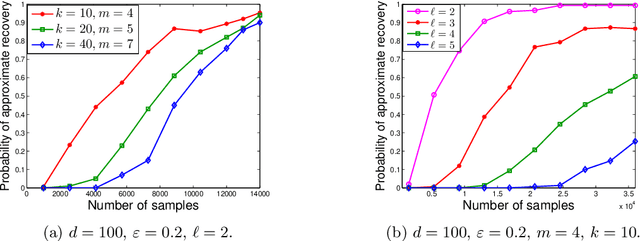

In the problem of multiple support recovery, we are given access to linear measurements of multiple sparse samples in $\mathbb{R}^{d}$. These samples can be partitioned into $\ell$ groups, with samples having the same support belonging to the same group. For a given budget of $m$ measurements per sample, the goal is to recover the $\ell$ underlying supports, in the absence of the knowledge of group labels. We study this problem with a focus on the measurement-constrained regime where $m$ is smaller than the support size $k$ of each sample. We design a two-step procedure that estimates the union of the underlying supports first, and then uses a spectral algorithm to estimate the individual supports. Our proposed estimator can recover the supports with $m<k$ measurements per sample, from $\tilde{O}(k^{4}\ell^{4}/m^{4})$ samples. Our guarantees hold for a general, generative model assumption on the samples and measurement matrices. We also provide results from experiments conducted on synthetic data and on the MNIST dataset.