 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much pretraining data do language models need to learn syntax?
Sep 09, 2021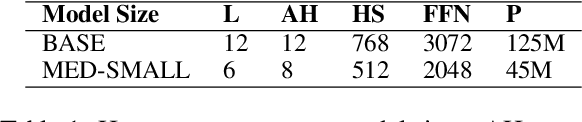
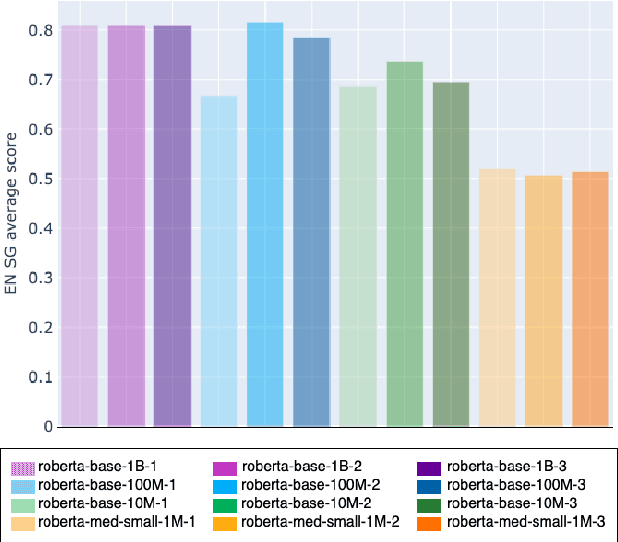
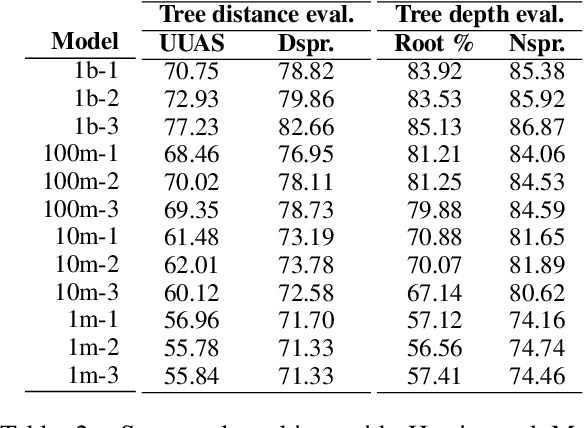
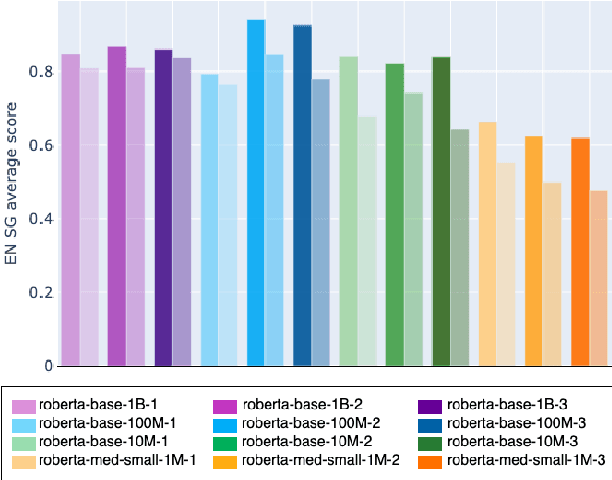
Transformers-based pretrained language models achieve outstanding results in many well-known NLU benchmarks. However, while pretraining methods are very convenient, they are expensive in terms of time and resources. This calls for a study of the impact of pretraining data size on the knowledge of the models. We explore this impact on the syntactic capabilities of RoBERTa, using models trained on incremental sizes of raw text data. First, we use syntactic structural probes to determine whether models pretrained on more data encode a higher amount of syntactic information. Second, we perform a targeted syntactic evaluation to analyze the impact of pretraining data size on the syntactic generalization performance of the models. Third, we compare the performance of the different models on three downstream applications: part-of-speech tagging, dependency parsing and paraphrase identification. We complement our study with an analysis of the cost-benefit trade-off of training such models. Our experiments show that while models pretrained on more data encode more syntactic knowledge and perform better on downstream applications, they do not always offer a better performance across the different syntactic phenomena and come at a higher financial and environmental cost.
Assessing the Syntactic Capabilities of Transformer-based Multilingual Language Models
May 10, 2021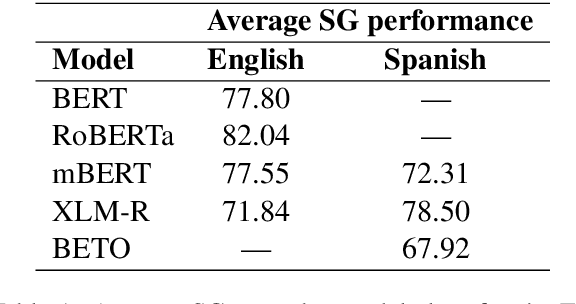
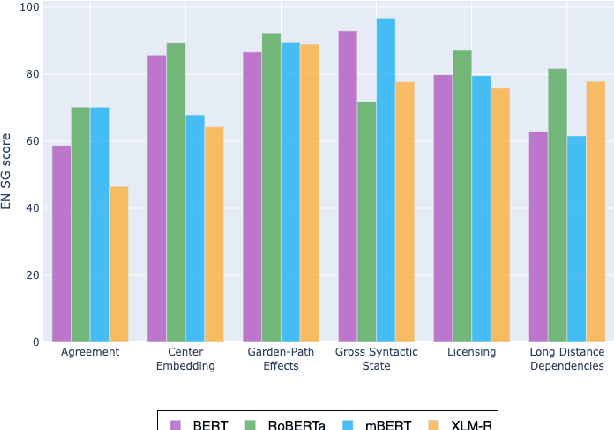
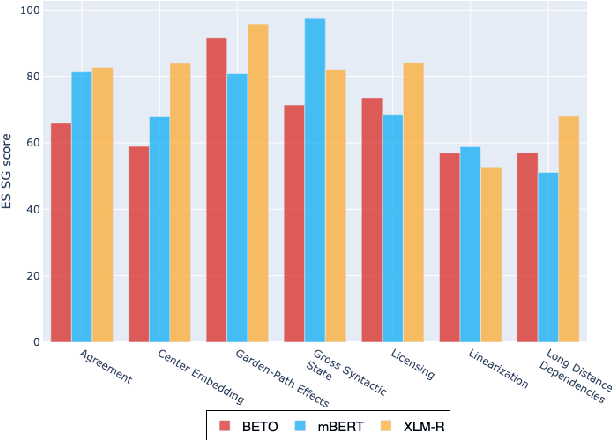
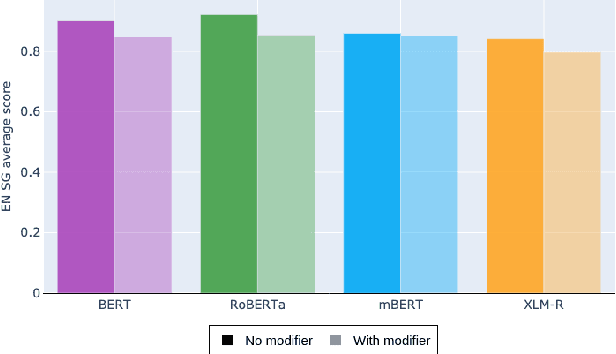
Multilingual Transformer-based language models, usually pretrained on more than 100 languages, have been shown to achieve outstanding results in a wide range of cross-lingual transfer tasks. However, it remains unknown whether the optimization for different languages conditions the capacity of the models to generalize over syntactic structures, and how languages with syntactic phenomena of different complexity are affected. In this work, we explore the syntactic generalization capabilities of the monolingual and multilingual versions of BERT and RoBERTa. More specifically, we evaluate the syntactic generalization potential of the models on English and Spanish tests, comparing the syntactic abilities of monolingual and multilingual models on the same language (English), and of multilingual models on two different languages (English and Spanish). For English, we use the available SyntaxGym test suite; for Spanish, we introduce SyntaxGymES, a novel ensemble of targeted syntactic tests in Spanish, designed to evaluate the syntactic generalization capabilities of language models through the SyntaxGym online platform.
On the Evolution of Syntactic Information Encoded by BERT's Contextualized Representations
Feb 10, 2021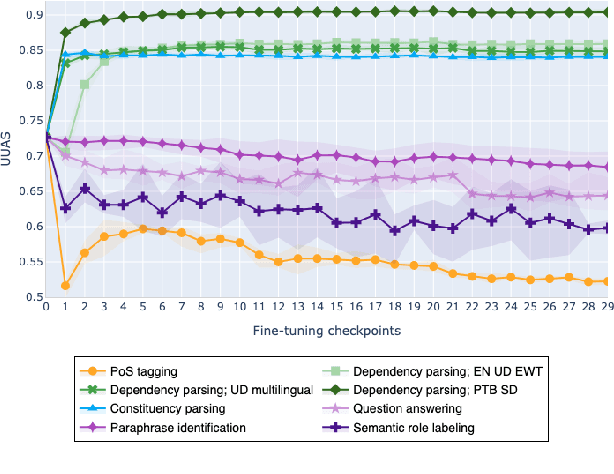
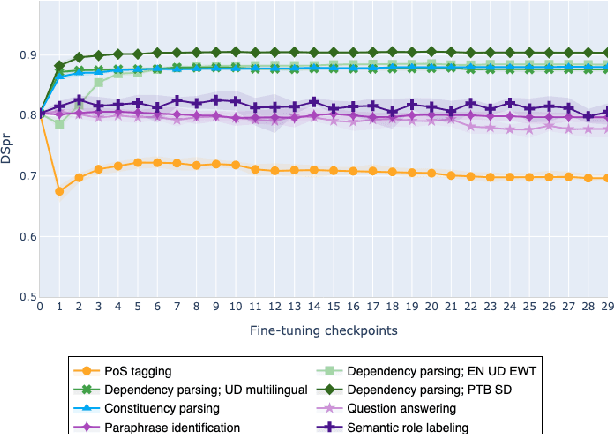
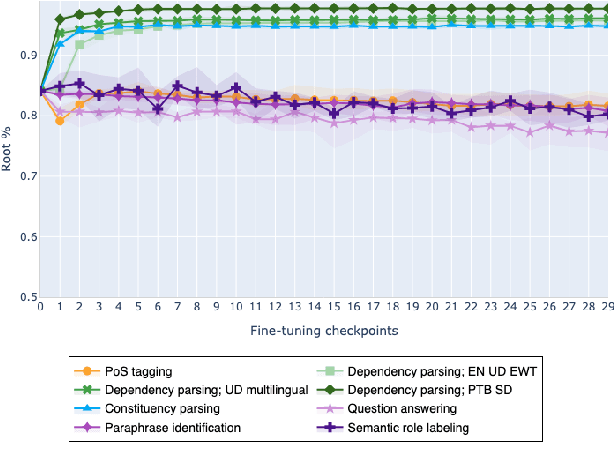
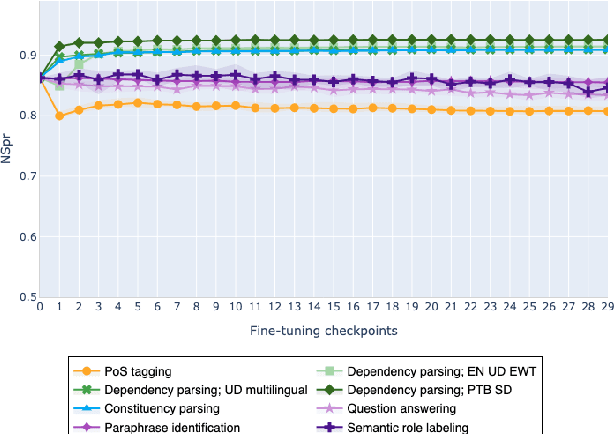
The adaptation of pretrained language models to solve supervised tasks has become a baseline in NLP, and many recent works have focused on studying how linguistic information is encoded in the pretrained sentence representations. Among other information, it has been shown that entire syntax trees are implicitly embedded in the geometry of such models. As these models are often fine-tuned, it becomes increasingly important to understand how the encoded knowledge evolves along the fine-tuning. In this paper, we analyze the evolution of the embedded syntax trees along the fine-tuning process of BERT for six different tasks, covering all levels of the linguistic structure. Experimental results show that the encoded syntactic information is forgotten (PoS tagging), reinforced (dependency and constituency parsing) or preserved (semantics-related tasks) in different ways along the fine-tuning process depending on the task.