 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
Jan 26, 2023



Text Summarization is a popular task and an active area of research for the Natural Language Processing community. By definition, it requires to account for long input texts, a characteristic which poses computational challenges for neural models. Moreover, real-world documents come in a variety of complex, visually-rich, layouts. This information is of great relevance, whether to highlight salient content or to encode long-range interactions between textual passages. Yet, all publicly available summarization datasets only provide plain text content. To facilitate research on how to exploit visual/layout information to better capture long-range dependencies in summarization models, we present LoRaLay, a collection of datasets for long-range summarization with accompanying visual/layout information. We extend existing and popular English datasets (arXiv and PubMed) with layout information and propose four novel datasets -- consistently built from scholar resources -- covering French, Spanish, Portuguese, and Korean languages. Further, we propose new baselines merging layout-aware and long-range models -- two orthogonal approaches -- and obtain state-of-the-art results, showing the importance of combining both lines of research.
Skim-Attention: Learning to Focus via Document Layout
Sep 02, 2021

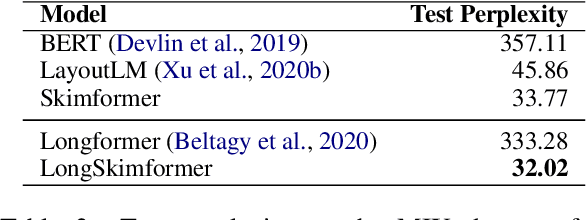
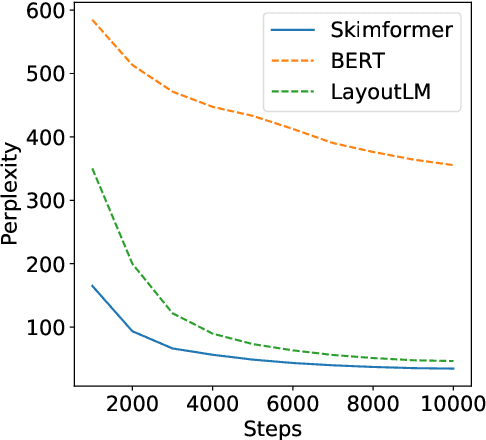
Transformer-based pre-training techniques of text and layout have proven effective in a number of document understanding tasks. Despite this success, multimodal pre-training models suffer from very high computational and memory costs. Motivated by human reading strategies, this paper presents Skim-Attention, a new attention mechanism that takes advantage of the structure of the document and its layout. Skim-Attention only attends to the 2-dimensional position of the words in a document. Our experiments show that Skim-Attention obtains a lower perplexity than prior works, while being more computationally efficient. Skim-Attention can be further combined with long-range Transformers to efficiently process long documents. We also show how Skim-Attention can be used off-the-shelf as a mask for any Pre-trained Language Model, allowing to improve their performance while restricting attention. Finally, we show the emergence of a document structure representation in Skim-Attention.